
2種類の値tを持つトレーニングデータ{(xn,yn,tn)}を正解/不正解に分類するパラメトリックモデルを立てて、パラメトリックモデルと不正解に分類されるトレーニングデータの距離E(w)が最小になるwを決定しモデルを作成するのがパーセプトロンであった。
E(w)においてトレーニングデータ(xn,tt)を定数として使用することでE(w)をwから決まる関数とし、wの決定をE(w)の最小化問題に帰着させる考え方は最小二乗法と同様であった。パーセプトロンは最小二乗法と異なり、E(w)の最小化問題を解析的に解けないため、数値計算によりE(w)を小さくする方向にwを更新する手順を取った。
最小二乗法はトレーニングデータから決定した多項式が未知のサンプルデータにおいても二乗誤差が最小になることを期待していたのと同様に、パーセプトロンも誤分類する未知のサンプルとの距離が最小になることを期待した分類モデルであることを意味する。最小二乗法もパーセプトロンも、サンプルデータのバラツキを考慮していない。
サンプルデータがモデルからσのバラつきをもって存在することを加味することで、パラメタwとバラつきσから決まる尤度関数を導入し、wの決定を尤度関数の最大化問題に帰着する最尤推定法に拡張した。最尤推定法により、パラメトリックモデルが変数とσの関数となり、確率的な回帰を検討できるようになった。
サンプルデータがモデルにより正解であると分類される確率を考慮することで、回帰モデルとして未来を予測する要素を増やすことができる。そこで、本エントリにおいてその手法(ロジスティック回帰)をまとめる。

ロジスティック回帰
モデルf(x,y)を仮定したとき、トレーニングデータ(x,y)について|f(x,y)|はモデルとの距離を表す。また、f(x,y)>0の方向にt=1のデータ、f(x,y)<0の方向にt=-1のデータが存在するモデルであることを示す。
f(xn,yn)tn > 0 であれば分類は正解であるから、f(x,y)が大きくなるにつれてt=1であるデータの発生確率が上がり、f(x,y)が小さくなるにつれてt=1であるデータの発生確率が下がることになる。逆に、f(x,y)が大きくなるにつれてt=-1であるデータの発生確率が下がり、小さくなるにつれてt=-1であるデータの発生確率が上がる。
横軸にf(x,y)、縦軸にt=1であるトレーニングデータがf(x,y)から得られる確率を取ると以下のような曲線が得られる。一般にロジスティック曲線と呼ばれる。
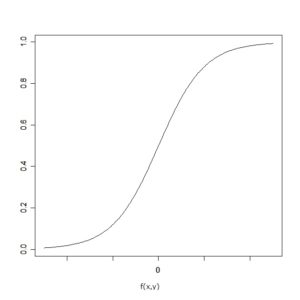
ロジスティック関数は以下のように表現される。
$$
\sigma(a)=\frac{1}{1+e^{-a}}
$$
トレーニングデータ(x,y)で得られたデータの特徴量tが1である確率は以下の式で表される。
$$
P(x,y) = \sigma(w_0 + w_1 x + w_2y)
$$
また、t=1の場合とt=-1の場合で確率が逆になるため
$$
\begin{eqnarray}
t_n=1の場合 &:& P(x_n,y_n) \\
P_n &=& P(x_n,y_n)^1\{1-P(x_n,y_n)\}^0 \\
&=& P(x_n,y_n) \\
t_n=-1の場合 &:& 1-P(x_n,y_n) \\
P_n &=& P(x_n,y_n)^0\{1-P(x_n,y_n)\}^1 \\
&=& 1-P(x_n,y_n) \\
\end{eqnarray}
$$
まとめて書くと以下となるが、これは全てのトレーニングデータがモデルから得られる確率であり尤度関数である。
$$
P_n = P(x_n,y_n)^{t_n}\{ 1-P(x_n,y_n)\}^{1-t_n}
$$
ここで、
$$
P_n = \sigma(w_0+w_1x+w_2y)
$$
だから、
$$
P_n = \sigma(w_0+w_1x_n+w_2y_n)^t{t_n}\{1-\sigma(w_0+w_1x_n+w_2y_n)\}^{1-t_n}
$$
多項式のベクトル表現をロジスティック関数に入れた結果をznとする。
$$
\begin{eqnarray}
w &=& \left (
\begin{array}{c}
w_0 \\
w_1 \\
w_2
\end{array}
\right ) \\
\phi_n &=& \left (
\begin{array}{c}
1 \\
x_n \\
y_n
\end{array}
\right ) \\
z_n &=& \sigma (w^T\phi_n)
\end{eqnarray}
$$
尤度関数Pnをznを使って表すと以下となる。
$$
P_n = z_n^{t_n}(1-z_n)^{1-t_n}
$$
尤度関数を最大とするwを決定する最尤推定法によりwを決定する方法をロジスティック回帰という。
ロジスティック回帰における尤度関数の最大化
パーセプトロンにおいて数値計算(確率的勾配降下法)によりwの修正値を求めwを更新していったのと同様に、ロジスティック回帰の尤度関数最大化問題も解析的に解くことができず、数値計算によりwを修正していく。ニュートンラフソン法を使った反復再重み付最小二乗法により修正値を求めていく。導出方法は別途記述。wの修正式は以下の通りである。
$$
w_{new} = w_{old}-(\Phi^TR\Phi)^{-1}\Phi^T(z-t)
$$
なお、各行列は以下の通りである。Rはzn(1-zn)を対角成分とする対角行列。
$$
\begin{eqnarray}
t &=& \left (
\begin{array}{c}
t_1 \\
t_2 \\
\vdots \\
t_n
\end{array}
\right ) \\
\Phi &=& \left (
\begin{array}{c c c}
1 & x_1 & y_1 \\
1 & x_2 & y_2 \\
\vdots & \vdots & \vdots \\
1 & x_n & y_n \\
\end{array}
\right ) \\
z_n &=& \left (
\begin{array}{c}
z_1 \\
z_2 \\
\vdots \\
z_n \\
\end{array}
\right) \\
\end{eqnarray}
$$
収束条件は以下の通り。ニュートン法の収束条件ぽい。
$$
\frac{||w_{new}-w{old}||^2}{||w_{old}||^2} < 0.001
$$
なお、wの更新が進み、ロジスティック関数znが0または1に近づくか、0または1そのものになる場合がある。
$$
z_n = \sigma (w^T \phi_n)
$$
zn=0または1となったとき、Rの対角成分zn(1-zn)が0となる。すると
$$
\Phi^TR\Phi
$$
の逆行列が存在しなくなりwを更新できなくなる。数値計算上の精度の話でもあるし、もともと全てのトレーニングデータが正解/不正解に分類できるのであれば、f(x,y)を大きくしていったときにf(x,y)と誤分類データとの距離が0になる、すなわちモデルから正解データを100%の確率で取得できる時がくるので、収束停止条件として考慮すべき内容である。