




ロジスティック回帰
2値の特徴量tを持つトレーニングデータ(x,y,t)を正解/不正解に分類する問題を考えたとき、最尤推定によりモデルf(x,y)を決めるのがロジスティック回帰。モデルf(x,y)がトレーニングデータ(x,y,t)を正解と分類する確率P(x,y)を立てて、P(x,y)の最大化問題を解くことでf(x,y)のパラメタを決定する。その際、P(x,y)はロジスティック関数を使って以下の通り表される。
$$
\begin{eqnarray}
z_n &=& \sigma(w^T\phi_n) \\
P(x,y) &=& z_n (1-z_n)
\end{eqnarray}
$$
P(x,y)において、トレーニングデータを定数とすることでP(x,y)をパラメタwに関する関数とした。P(x,y)を最大化するwを求めたいのだが、P(x,y)を解析的に最大化することはできず、パラメタwを数値計算(反復再重み付最小二乗法、ニュートンラフソン法)することによりf(x,y)のパラメタwを更新していく。wが一定値に収束した場合、f(x,y)=0はトレーニングデータ内の正解データ(t=1)を1/2の確率で正解(t=1)として分類できることを示す。
正解分類確率の制御
トレーニングデータ(x,y,t)に対して、f(x,y)t>0の場合は「正解」、f(x,y)t<0の場合は「不正解」と定義しており、f(x,y)>0の方向あるt=0のデータ、f(x,y)<0の方向にあるt=1のデータは
「不正解」であるから、多項式をf(x,y)>0の方向に距離α分平行移動していくと、f(x,y)>0のときは正解であったもののf(x,y)>αのときは不正解となるデータが発生する。
逆にf(x,y)<0の方向に距離β分平行移動していくと、f(x,y)<0のときは正解であったもののf(x,y)<-βのときは不正解となるデータが発生する。
言い換えると、トレーニングデータを「正解」として抽出する確率が1/2であるポイントf(x,y)=0を中心に、f(x,y)を移動することでトレーニングデータを「正解」として分類する確率を増減させることができる。
例えば、f(x,y)>0方向にα移動することで、トレーニングデータを「正解」として分類する確率を50%から75%に変更する等の操作にあたる。
ロジスティック回帰とROC曲線
分類問題を整理すると、分類対象とするトレーニングデータの特徴量tを2値のいずれであるか識別することであり、分類とその結果の組み合わせとして以下の組み合わせが考えられる。それぞれ統計の分野で名前が付いている。
- t=1であるデータを1として分類する TP, True Positive
- t=1であるデータを0として分類する FN, False Negative
- t=0であるデータを0として分類する TN, True Negative
- t=0であるデータを1として分類する FP, False Positive
かなり混乱するので図を張り付けておく。観測データが1なのか0なのかは”Positive”/”Negative”、それを1と分類したのか0と分類したのかは”True”/”False”。t=1/0は符号に過ぎないので”Positive”/”Negative”はその時次第。True/Falseは分類結果が特徴量と一致するかどうかを表す。
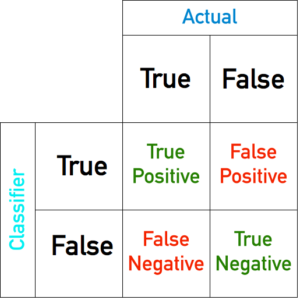
ロジスティック関数P(x,y)=σ(w0+w1x+w2y)は、トレーニングデータ(x,y)を1として分類する確率を返す関数である。
最尤推定によりwを求めたのだから、f(x,y)=w0+w1x+w2yは、確率的に最もトレーニングデータを正しく分類する多項式となっている。
“確率的に最も”の度合いを定量的に表すのがROC曲線とAUC。
全トレーニングデータ(x,y)に対してP(x,y)を計算し降順ソートすると、P(x,y)が高ければ(つまり上位であれば)t=1のデータが多いはずで、P(x,y)が低ければ(つまり下位であれば)t=0のデータが多いはずだ。P(x,y)に相当するTP,FPが期待される。実際には上位にt=0のデータ、下位にt=1のデータが観察されることがあり、単純にP(x,y)からTP,FPが決まるものではない。
TPがP(x,y)よりも相対的に高く、(1-P(x,y))よりも相対的に低ければ、多項式の性能が良いということになる。
定数c=P(x,y)を定めたときP(x,y)<c<1の範囲でt=1のものは True Positive, P(x,y)<c<1の範囲でt=0のものは False Positive。0<c<P(x,y)の範囲でt=0のものは False Negative, t=1のものは False Positive。cを1から0に下げていくと True Positive, False Positiveの数がそれぞれ独立に増加していく。各々のcを真陽性率、偽陽性率という。
横軸に偽陽性率FP、縦軸に真陽性率TPをとり、トレーニングデータ(x,y)をプロットした図がROC(Receiver Operating Characteristic)曲線。
P(x,y)を1から0に減らしていったときTP/FPそれぞれ増加するが、ROC曲線によりTPが大きくFPが小さいプロットが性能の良い分類であることを視覚的に表現できる。
ROC曲線の左下と右上を結ぶ直線は、0<P(x,y)<1の全域に渡りFP=TPであったことを示し、ランダムにTrueかFalseかを答えたときの視覚的表現にあたる。
左上に凸となっているROC曲線が性能の良さを表し、ROC曲線の下の面積AUC(Area Under the Curve)が分類器の性能を表す数値。
