




この記事はSnowflake Advent Calendar 2023シリーズ2の19日目です。
今年はSnowProAdvanced: Architect試験に合格できました。
結局のところ資格試験であるという側面はあるものの、いろいろ役立っている実感があります。
その後、Mediumというメディアで気になる記事を読み漁る、みたいなことを始めました。
正直知らないことばかりです..。
いくつか読んだ記事のうち、これはヤバいなと感じた記事の読書感想文を書こうと思います。
Snowflake’s Data Cloud provided as Software-as-a-Service (SaaS), enables data storage, processing, analytic solutions, Machine Learning, and running apps & services in a performant, easy-to-use, and flexible manner using “virtual warehouses” which is the primary compute primitive in Snowflake. This post details the internals of virtual warehouses which provide elastic, highly available, and fully managed mechanisms to run a variety of customer workloads on multiple cloud service providers.
訳は間違っているところもあると思います。ご容赦ください。
【目次】
- ∨仮想ウェアハウスの基本
- ∨仮想ウェアハウスのサイズとタイプ
- ∨マルチクラスタ ウェアハウス
- ∨柔軟性-ステートレスなスケーリング
- ∨柔軟性-マルチクラスタ オートスケーリング
- ∨柔軟性-ゼロへのスケール
- ∨柔軟性-自動Suspend期間の管理
- ∨柔軟性-ウェアハウス内のVMは起動済みVMのプールから割り当てられる
- ∨柔軟性-需要のバーストに対して用意されるQAS
- ∨仮想ウェアハウスのジョブスケジューリング
- ∨並列レベルの制御
- ∨リソースモニタと使用量制限
- ∨ウェアハウスの負荷とサイズの決定方法
- ∨ストレージ・キャッシュ-ストレージアーキテクチャ
- ∨ストレージ・キャッシュ-キャッシュ戦略
- ∨マルチテナント環境におけるセキュリティとリソース分離
- ∨ネットワークセキュリティ
- ∨Python/Scala/Javaコードの分離
- ∨ソフトウエア更新の管理
- ∨将来の機能
- ∨まとめ
仮想ウェアハウスの基本
まず、コンピュートとストレージが分離し、それぞれ独立してスケールできることが特徴としている。
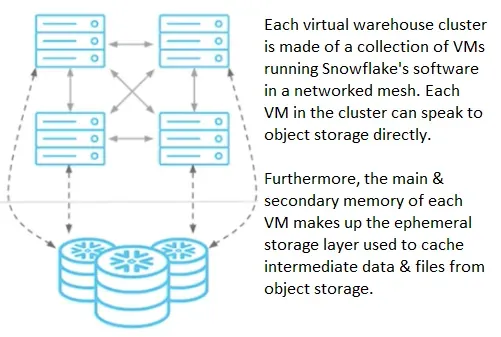
Snowflakeにおいて、仮想ウェアハウスはコンピュートの最小単位ではあるが、仮想ウェアハウスは
複数のVMからなるMPPクラスタであると言及している。
この記事は、仮想ウェアハウスを説明するために仮想ウェアハウスを構成するVMに言及している。
仮想ウェアハウスの下に物理のVMがいることにフォーカスがあてられている。
SnowflakeのSaaSサービスを実現するコードはMPPクラスタを構成する各VMで動いていて、
ジョブ実行の際、各VMはリソースを直接参照するしVM同士でmeshN/Wを構成して資源を共有する。
(後述) 仮想ウェアハウス同士はストレージを共有しないけれど、仮想ウェアハウス内部のVMは
むちゃくちゃ密に連携しあって、計算資源もストレージも共有しあう。
このセクションで、仮想ウェアハウスの設計方針が述べられている。
「可能な限り顧客に選択肢を提供するのを避けSnowflakeがベストを考える」が基本方針である一方、
「仮想ウェアハウスを構成するVMの物理資源を変更できる柔軟性を提供する」と言っている。
以降、仮想ウェアハウスを構成するVMの振る舞いについて書かれている
仮想ウェアハウスのサイズとタイプ
仮想ウェアハウスのタイプはCPUとメモリの比率、サイズはCPUとメモリの総量を決める。
タイプは、StandardとSnorpark-optimizedの2種類。
Snowpark-optimizedは、Standardの16倍のメモリ量と10倍のSSDを持つ。
メモリ増量により計算が高速化する。ストレージが大きいとキャッシュや中間生成物が
後続の実行で再利用され高速化する。
中間生成物の書き込みに対し、第1に仮想ウェアハウス上のVMのメモリが使われる。
メモリを使い切ったとき、VMのローカルSSDが使われる。
SSDも使い切ったとき、S3等のリモートストレージが使われる。
QUERY_HISTORY viewにSSD、リモートストレージにスピルした量を出力するので、
メモリが溢れないようにするか、少なくともSSDには乗るようにサイズを増やせよ、と言っている。
(やはりストーリーがストレートでわかりやすい..)
SELECT QUERY_ID
,USER_NAME
,WAREHOUSE_NAME
,WAREHOUSE_SIZE
,BYTES_SCANNED
,BYTES_SPILLED_TO_REMOTE_STORAGE
,BYTES_SPILLED_TO_REMOTE_STORAGE / BYTES_SCANNED AS SPILLING_READ_RATIO
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
WHERE BYTES_SPILLED_TO_REMOTE_STORAGE > BYTES_SCANNED * 5 - Each byte read was spilled 5x on average
ORDER BY SPILLING_READ_RATIO DESC
;
マルチクラスタ ウェアハウス
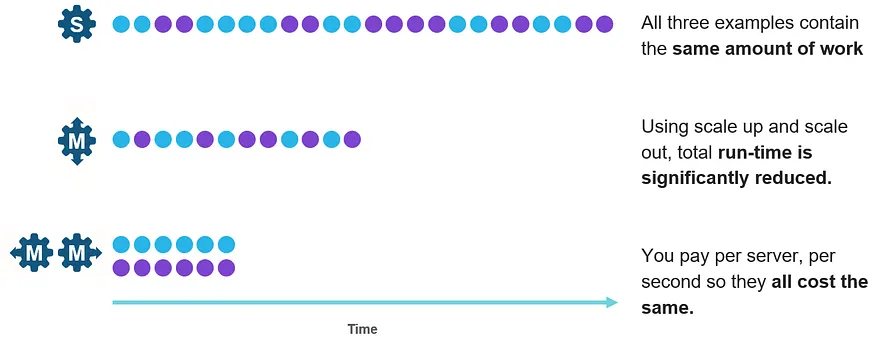
マルチクラスタは、ジョブの同時実行性を高めるためにクラスタを静的/動的に追加する仕組み。
クラスタ内のVMは相互に関係し合いリソース共有して複数台でジョブのオフロードを行うため、
単一クエリのパフォーマンスアップに寄与する。一方で、クラスタ間はリソース共有しないため、
増えたクラスタ内のVMはジョブのオフロード先の融通にはならず、同時実行時の性能劣化予防に働く。
他にスケーリングポリシーの話や、Min/Max設定による静的/動的追加の話が書かれているが省略。
UpではなくOutの方が費用対効果が高い例として、interleaved workloadsが挙げられている。
Outで増やしたクラスタがダラダラと回り続けるケースが除外できず理論値ではあるけれども、
Upに対するOutのメリットを言う場合に説明しやすい図だなと思った。
この辺りモヤモヤしていたのでバシっと説明してもらえて助かりました。
柔軟性-ステートレスなスケーリング
需給調整の文脈ではなく、自動起動と自動サスペンドの文脈で仮想ウェアハウスの状態が書かれている。
リソースがステートレスであれば、需要の増減と関係なくリソースを増減できる。
仮想ウェアハウスはステートレスリソースであって、需要の発生によりプロビジョンングされ、
需要の消滅により仮想ウェアハウスに紐づくリソースが破棄される。
仮想ウェアハウスにジョブが送信されると、クラスタ内のVMはジョブ実行中にのみ存続するプロセスを
生成する。プロセスが失敗した場合、自動的に再試行される。
ユーザとウェアハウスは多対多の関係であり、ウェアハウスから見ると同時に複数の需要が発生する。
異なる組織・部署がウェアハウスを使用するケースにおいて、ウェアハウスは同時にそれぞれを処理する。
各々のウェアハウスは同じ共有テーブルにアクセスできるが、その際、データのコピーをウェアハウス内に
持たなくても良いように作られているので、各組織・部署の処理が他の組織・部署に暴露されるリスクを
回避できるようになっている。
異なる組織・部署が実行したジョブがウェアハウス上で相互作用しない、という事実があり、
組織・部署から見れば、他の組織・部署に全く影響されず自由にウェアハウスを利用できるという
書き方になっていて、ちょっと抽象度が高いですが「ステートレス」が説明されていました。
柔軟性-マルチクラスタ オートスケーリング
スケーリングポリシーの説明。
スケーリングポリシーの設定により、各クラスタの自動起動・シャットダウンの相対的な速度を制御する。
スタンダードポリシーはクレジット消費削減よりもクラスタ追加を優先し、クエリ所要時間を最小化する。
エコノミーポリシーの設定により、クラスタを追加するよりも現在実行中のクラスタを全開で回すことが
優先され、結果としてクエリがキューに入りやすくなり所要時間が延びるが、クレジット消費は減る。
この説明は公式通り。
柔軟性-ゼロへのスケール
Auto-resumeとAuto-suspendの説明。
ウェアハウスに対する需要がなくなって一定期間経ったら自動的に停止する。
ウェアハウスに対する需要が発生したら自動的に再開する。その時間等を調整できる。
これらの設定はクラスタではなくウェアハウスに対して設定する。
これも説明は公式通り。需要がなくなったら1個も起動していない状態にできることが主張ポイント
柔軟性-自動Suspend期間の管理
Suspendは、つまり仮想ウェアハウスを構成するVMのリリースなので、VMが持つSSDに
蓄えられたキャッシュは同時に破棄されてしまう。これは、後続のジョブが発生したときに
クエリ結果キャッシュが効かなくなることに繋がる。
公式の通り、「ウェアハウス稼働時間(クレジット消費)」と「クエリパフォーマンス」がトレードオフの
関係となる。需要がなくなってすぐにウェアハウスを止めると確かにクレジット消費は減るが、
キャッシュヒット率が下がる。トレードオフにSweet spotがあるので探しましょうと書かれている。
これに留まらず、どういう風に決めたら良いかガイドが書かれている。
ただ、これは答えが無い問題で、実験してねとも書いてある。
– タスク実行、ロード、ETL/ELTユースケースにおいて、すぐに止めた方が良い。
– BI等SELECTが起きるユースケースは、止めるまで10分待つべき。
– DevOps,DataOps,Data Scienceのユースケースは、停止時間は5分が最適。
とりあえず、タスク実行、ロードでは、自動Suspend期間を持たせる意味はないので、
そこは、バッサリ最速で落とす勇気が出る書き方で参考になりました。
全てのクエリのうち、SSDからスキャンした割合を集計するクエリは以下。
この割合が低いということは、ウェアハウスのSuspendが早すぎることを示している。
SELECT WAREHOUSE_NAME
,COUNT(*) AS QUERY_COUNT
,SUM(BYTES_SCANNED) AS BYTES_SCANNED
,SUM(BYTES_SCANNED*PERCENTAGE_SCANNED_FROM_CACHE) AS BYTES_SCANNED_FROM_CACHE
,SUM(BYTES_SCANNED*PERCENTAGE_SCANNED_FROM_CACHE) / SUM(BYTES_SCANNED) AS PERCENT_SCANNED_FROM_CACHE
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."QUERY_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
AND BYTES_SCANNED > 0
GROUP BY 1
ORDER BY 5
;
柔軟性-ウェアハウス内のVMは起動済みVMのプールから割り当てられる
VMをコールドから起動するには10秒オーダーの時間がかかる。そもそも小規模のクラウドサービスでは
VMの数が不足して流動性がない場合もあり、起動済みのVMをプールして再利用することで、
これらの問題を解決しようとしている。
Snowflakeは、VMの起動、終了、停止、再開、スケーリング等のオペレーション時間に対して、
内部でサービスレベル目標を設けている。
(これらの時間がサービスレベル目標から外れるとSnowflake内部でインシデント管理されるらしい。)
ユーザのリクエストで需要が発生した場合、起動済みVMのプールからVMが選ばれ、
ウェアハウスに割り当てられる。
起動済みVMのプールのサイズは、過去の需要のベースラインとスパイクから予測されているらしい。
確かにウェアハウスが瞬時に起動する仕組みが気にはなっていました。
妥当な仕組みで成立しているようですが、言及されている点がポイントかと思います。
柔軟性-需要のバーストに対して用意されるQAS
サイズアップの他にQAS(Query Acceleration Service)というサービスが存在する。
起動済みVMプールにあるVMを需給に応じて自動的にウェアハウスに組み入れる。
ウェアハウス内でVMは密に連携してクエリをオフロードし合う。
動的なサイズアップであって、疎連携のマルチクラスタとは異なる。
QASは主に、巨大なテーブルのScanや、burstyなワークロードを目的とする。
QASを使用すると、大規模なクエリが検知された場合にウェアハウス内のVMが
ウェアハウスから離れ、他のユーザの小規模なクエリに使われるらしい。
通常はウェアハウスのサイズアップよりも低いコストで目的を達成できるそう。
この手の機能が何故ワークロードを高速化するのか、結局のところ中身を知らないとわからないと
思うので、機能の説明の他に、どういう作りなのかを書いてくれるととても参考になる気がする。
When to useはburstyなワークロードということ。
QASで恩恵を受けられるクエリがどれぐらいあるか気になるところ。
公式によると以下の特徴を持つクエリはQASの恩恵を得られないそう。
- フィルターや集計(つまり、 GROUP BY)がない。Query Acceleration Serviceは現在、このようなクエリを高速化できません。
- フィルターの選択性が十分ではない。または、 GROUP BY 式のカーディナリティが高くなっている。
- 十分なパーティションがない。スキャンするために十分なパーティションがないと、クエリアクセラレーションの利点は、サービス用に追加のサーバーを取得する際の待機時間によって相殺されます。
- クエリに LIMIT 句が含まれている。ただし、 ORDER BY 句を含んでいる LIMIT 句はサポート されます。
QASの恩恵を得られるクエリとウェアハウスは以下のビューから探すことができる。
-- アクセラレーションの対象となるクエリ実行時間の量によって、
-- サービスから最もメリットを受ける可能性のあるクエリを識別します。
SELECT query_id, eligible_query_acceleration_time
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE
ORDER BY eligible_query_acceleration_time DESC;
-- Query Acceleration Serviceの特定の期間中、
-- 対象となるクエリが最も多いウェアハウスを識別します。
SELECT query_id, eligible_query_acceleration_time
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE
WHERE warehouse_name = 'mywh'
ORDER BY eligible_query_acceleration_time DESC;
QASにより、ウェアハウスは需給調整のためにVMをリース(借りる)する、という表現がある。
ウェアハウスがリースできるVMの数の最大値は、Scale Factorという数値で表される。
要は、通常のウェアハウスサイズで確保するVMの数の何倍のVMをリースできるか。
例えば、Scale Factorが5、VMのサイズがM(つまり4credsits/hour)の場合、
4*5=20 credits/hourまで増強することになる。
Scale FactorはQUERY_ACCELERATION_ELIGIBLEビューにあり、
クエリID単位で知ることができる。
SELECT MAX(upper_limit_scale_factor)
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_ACCELERATION_ELIGIBLE
WHERE warehouse_name = 'mywh';
仮想ウェアハウスのジョブスケジューリング
スループット最大化、レイテンシ最小化、クラスタ使用率最大化、異なる需要に対して供給のために、
ウェアハウスの負荷を追跡・調整するウェアハウススケジューリングサービス(WSS)が備わっていて、
クエリがクラウドサービスレイヤでコンパイルされた後、WSSがジョブスケジューリングを行う。
WSSは各VMのCPU・メモリ使用量を追跡する。ウェアハウスのメモリキャパシティは、
各VMの実効メモリ(OSやソフトウエアの使用を除く)にウェアハウス内のVMの数を掛けたもの。
メモリが使い果たされたことを検知して、データをdiskに吐き出す(Spill)。
メモリ負荷が高くなりすぎると、VMは落とされて”リタイア”(前述)する場合がある。
情報科学の用語の1つにDOP(Degree Of Parallelism)がある。
WSSは1個のジョブを何個のプロセスで同時処理して完了するか、という制御を行なっているらしい。
VMのCPUコアが1つのプロセスを受け持ち、CPUコアの数だけプロセスを並列実行できる。
例えばCPUコアを8個もつVMを4個もつウェアハウスの保持コア数は合計32個。
1つのジョブを32コアで並列処理しても良いし、逆に32個のジョブを1コアで処理しても良い。
DOPはコンパイル時に推定される。
以降、ジョブスケジューリングの少し詳しい説明が書かれている。
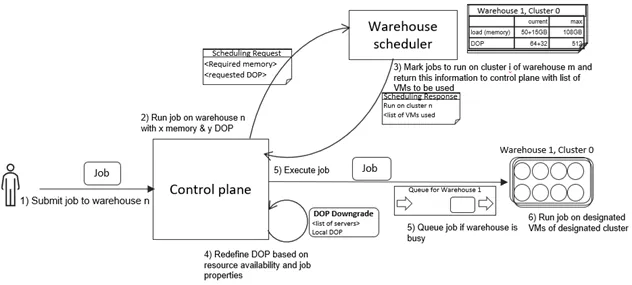
実行中の各ウェアハウスは既にキューにジョブが積まれている。
その上で新しいジョブを処理する場合、どのウェアハウスで処理すべきかを決めることになる。
WSSはウェアハウスの全てのVMに均等に負荷分散されるべき、という仮定を立てる。
クラウドサービスレイヤは、ジョブの処理に必要なメモリとコンパイル時に決まったDOPから、
そのジョブをどのウェアハウスで処理するかを決める。
メモリの使用状況や同時実行性(?、キューに積む時点でジョブがどれぐらい並列実行されているか??)
を見て、ウェアハウスの適格性を決める。適格性が同じなら、その時点で同時実行ジョブが最も少ない
ウェアハウスを選択する。適格なウェアハウスが無い場合、WSSキューに残り続ける。
ジョブスケジュールを行うと、各ウェアハウスのリソース使用状況バランスが変化する。
WSSはクラウドサービスにVM使用状況のレポートを送る。
クラウドサービスは状況次第でDOPを下げる(より少ない並列度で処理するよう計画される)。
DOPを下げた後、ジョブはウェアハウスで実行される。ジョブ終了後リソースは解放される。
負荷に応じてDOPがダイナミックに調整されている様が書かれている。
実際のところ、DOPの推移を観察することはできないのと、DOPの上げ下げとパフォーマンスの
関連が本当にその通りなのか不明なこともあり、結局良くわからない。
並列レベルの制御
MAX_CONCURRENCY_LEVELパラメタにより、最大並列処理数を設定できる。
デフォルト値は8ということなので、最大で4個のジョブを並列実行することになる。
巨大なクエリを処理する場合、1個のジョブを受け持つコア数を増やすことでスループットが上がる
場合があるらしい。並列処理数が下がるとキューに積まれるジョブが増えることに繋がる。
ウェアハウスサイズを増やさずにMAX_CONCURRENCY_LEVELだけ調整しても、
リソースの総量は変わらないはずだし、簡単に最適値が見つかるなら全自動で決めてくれる
のだろうから、きっと難しい話なのだろう。QASみたいに全然違う何かを使うと良いよ、と書かれている
これは公式の以下のドキュメントが対応する。
同時実行クエリの制限
リソースモニタと使用量制限
クレジットを想定よりも多く消費しないようにするアラートとハードリミットの仕組み。
消費クレジットが制限を超えたことをトリガにアラート、自動停止を実行できる。
リソースモニタが設定されていないウェアハウスを以下のクエリで見つけて設定せよとのこと。
SHOW WAREHOUSES
;
SELECT "name" AS WAREHOUSE_NAME
,"size" AS WAREHOUSE_SIZE
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE "resource_monitor" = 'null'
;
ウェアハウスの負荷とサイズの決定方法
Snowsightでウェアハウスの負荷を確認できる。これの計算方法などが書かれている。
確かに、あれ、何をどうやって集計したチャートなのか知らなかった。
Snowflakeが出力するメトリクスを見てウェアハウスの正しいサイズを決定せよとのこと。
ウェアハウスのジョブ負荷メトリクスは、一定期間内の実行ジョブ数、キューに入ったジョブ数の
平均である、とのこと。実行ジョブ数の平均は、全てのジョブの実行時間(秒)を期間(秒)で
割った値であるとのこと。これはバーの青色の部分だな。
Private Previewで、ウェアハウスの使用率メトリクスが用意されるらしい。
以下の表のように、ウェアハウス単位、クラスタ単位で100分率の値を得られる。

ウェアハウス負荷や使用率によって、キャパシティ割り当てを行うべきとのこと。
どういう数字だったらどうすべきか書かれている。そういえば知らなかった。
ワークロードのスループット・レイテンシが適切で、キューに入ったクエリが少なく、
長期にわたりクエリ負荷が1未満、かつ、使用率が50%を切る場合、
ウェアハウス・クラスタのダウンサイズを検討する。別のウェアハウスを起動し、
キューに入れられたジョブをそのウェアハウスで実行できるようにする。
ワークロードのスループット・レイテンシが期待よりも低速で、かつ、
クエリ負荷が低く、かつ、使用率が75%を超えるなど高い場合、
ウェアハウスのアップサイズを検討するか、クラスタの追加を検討する。
使用量の急増(スパイク)が繰り返し発生する場合、
ウェアハウスの追加・クラスタの増量を行い、スパイクに対応するクエリをそれに移す。
スパイク以外のクエリを小さいウェアハウス・クラスタで実行されるようにする。
ワークロードが通常よりも大幅に高い場合、
どのジョブが負荷に寄与しているのか調査する。
ウェアハウスが定期的に実行される(スパイクではない)が、かなりの期間にわたって
合計ジョブ負荷が1未満である場合、
ウェアハウスのサイズダウン、クラスタの削減を検討する。
ストレージ・キャッシュ-ストレージアーキテクチャ
Snowflakeには、テーブルの永続化、JOIN等のクエリ演算子によって生成されクエリの実行中に消費される
中間データの2つの形式のストレージがある。
永続化テーブル
寿命が長い永続化テーブルは、S3等のオブジェクトストレージが使われる。
オブジェクトストレージは比較的スループットが高くないが、長期間保管する際の可用性要件が良い。
S3等のブロックストレージに対して一括上書きすることになるが、immutableなデータを
扱うには適している。ブロックストレージの上でimmutableなデータの水平展開を行う。
(別のMedium記事で、micro-partitionはテーブルのバージョニングであって、immutableな
データ領域を重ねていくことと、その仕組みにより副作用的にTime-Travelが用意されることが
書かれている。micro-partitionがブロックストレージ上で増えていく様は面白い)
immutableなファイルには列データ、属性データがグルーピング・圧縮され格納されている。
相対位置が付与されていて再構成しやすい。
ブロックストレージに備わっている「部分的な読み取り」機能により、これらのファイルの
必要な部分を取得する。こうして永続化テーブルがブロックストレージに保管・使用される。
JOIN等のクエリ演算子によって生成されクエリの実行中に消費される中間データ
中間データは寿命が短く低レイテンシ・高スループットが求められる。
ジョブの実行にウェアハウスのメインメモリとSSDが使われる。
これらはウェアハウスの開始時に作られ、終了時に破棄される。
これらの一時ストレージは、リモートにある永続化テーブルのライトスルーキャッシュとして機能する。
各仮想ウェアハウスはそれぞれ個別に一時ストレージを持ち、クエリ実行時に使用される。
この一時テーブルは、全ての仮想ウェアハウスから”個別にコピーすること無しに”共有できる。
メモリ管理を単純化するためのSpill
中間データの書き込み操作の際に、まずウェアハウス内のメインメモリが使われる。
メインメモリがfullになると、ウェアハウスのローカルdisk(SSD)が使われる。
ローカルdiskがfullになると、リモートストレージが使われる。
メモリ不足、ディスク不足を回避するための仕組みになっている。
事実としては良く知られた挙動だけれども、それと「メモリ管理の単純化」というストーリーが
紐づいて理解しやすくなった気がする。
ストレージ・キャッシュ-キャッシュ戦略
「キャッシュ」とは、良く使うデータを取り出しやすいところに一時的に保存しておくもの。
キャッシュ容量は限られるため、ヒット率を維持しつつ効率的に中身を更新することが重要。
その具体的な仕組みとして、LRU (Least Recently Used)、LFU (Least Frequently Used)が有名。
キャッシュが必要な中間データ(前述)量が小さい場合、一時ストレージレイヤ(=VMのdisk)は、
ファイル名のハッシュ値を使ったLRUキャッシュにより、頻繁にアクセスする永続化データの
キャッシュとして使われる。このキャッシュは低優先度で”lazy”に行われるらしい。
ファイルが仮想ウェアハウスのどのVMにストアされるかについて「一貫性」が言われている。
一方向関数にファイル名を食わせた結果、ファイル名とストア先VMが決まることを言っている。
サイズ変更によってVMの追加・削除が行われる際にキャッシュがシャッフルされてしまわない。
(VMのサイズが同じならば)永続化ストレージ上のファイルは特定のVMに保存されるため、
永続化ストレージ上のファイルに対する操作は、そのファイルのハッシュが保存されるVMが
実行するようにスケジューリングされる。こうして、ジョブの並列化はファイルのハッシュ値が
一貫して同じVMに保存されることと密接に結びついている。
ファイル名が偏っているとハッシュも偏り、保存先のVMが偏る場合がある。
それを回避するため、ワークロードがそのVMでの所要時間が他のVMでの所要時間よりも
小さいかどうか、に基づいてクラスタ内のVM内でロードバランシングが行われる。(え..?)
キャッシュ(execution artifacts)が移動した場合(キャッシュアウトした場合)、
最初に実行がスケジュールされていた既に過負荷になっているVMの負荷がさらに増加する
のを避けるため、操作の実行に必要なファイルが永続化ストレージから読み取られる。
仮想化の問題、ネットワークの問題など様々な理由で一部のVMが極端に遅い時があるらしい。
その対策にもなっているらしい。
Snowflakeのスケジューリングロジックは、execution artifactsを永続化ストレージ
のキャッシュ先と同じVMに配置することと、全てのexecution artifactsを少数のVMに
配置することの間のバランスを見つけようとする。
前者は永続化ストレージのReadに伴うネットワークトラフィックの最小化を目指すが、
ジョブがウェアハウス内の全てのVMにスケジューリングされることによって中間データが
VM間でやり取りされることに起因してネットワークトラフィックが増加するリスクもある。
後者は中間データ交換のためのネットワークトラフィックがなくなる(減る..?)が、
永続化ストレージのReadのためのネットワークトラフィックが増加する可能性がある。
一時データ容量はリモートの永続化ストレージ容量よりもかなり小さい(平均0.1%未満)
にも関わらず、Snowflakeのキャッシュスキーム上では、Readのみのクエリで-80%、
Read-Writeがあるクエリで-60%のキャッシュヒット率にもなるらしい。
文章だけでは読みきれないな..。ただキャッシュの仕組みが書かれているだけでなく、
永続化ストレージ上のデータ(=ファイル)をVMに持ってくる仕組みの説明になっていて、
ウェアハウス内のVMで負荷分散して処理していく様が薄ら分かった気がする。
マルチテナント環境におけるセキュリティとリソース分離
アカウント、ジョブごとにデータを分離し、アカウント、ジョブ間でデータが漏洩しないように
設計している。”仮想マシンを分離すること”により、各テナントの分離を実現している。
さらに、cgroup、カーネル名前空間、seccomp(※)のようなDockerコンテナに似たカーネルプリミティブ
を備えたVM内のサンドボックスにより、同一顧客アカウント内のジョブ間の情報漏洩を防ぐ。
※cgroup,カーネル名前空間,secompはLinuxカーネルの機能で、
Dockerコンテナの内部で使われている。
cgroup,namespaceは、プロセスグループのリソース(CPU、メモリ、ディスクI/Oなど)の利用を
制限・隔離するLinuxカーネルの機能とのこと。seccompは自プロセスが発行するシステムコールを
制限してプロセスを乗っ取られたとしても被害を最小限にする機能とのこと。
各VMを独自のハードウェア、ページテーブル、カーネルを使用して動作させることで、
マルチテナントセキュリティとリソース分離を図っている。
VMが同じハードウェア、ページテーブル、カーネルを使用した”VM分離”がない場合、
従来から使われているカーネルカーネル共有方式(cgroup,名前空間,secomp付き)だけでは、
Snowflakeのセキュリティ基準に達しないと判断したそう。(そうですか..)。
“VM分離”するよりもカーネルを共有した方が、コンテナは高速に起動して都合が良いけれども、
カーネルを共有するということは、過去のCVEsから予想されるセキュリティ脆弱性に曝露される
ことになる。
仮想ウェアハウスを構成するVMはそのウェアハウスが占有するプライベートなリソースであって、
仮想ウェアハウス間で共有されたりはしない。加えて仮想ウェアハウスはステートレス。
データの状態に影響されず、需要に応じてどんな時でも作成・破棄・リサイズできる。
その仕組みのため、ジョブが特定の仮想ウェアハウスで限定して実行されるから、
その仮想ウェアハウスのパフォーマンスが他の仮想ウェアハウスのパフォーマンスに影響しない。
ジョブ実行の際、各仮想ウェアハウス内のVMが新しいプロセスを起動する。
そのプロセスはジョブの実行期間中にのみ生存する。
プロセスの失敗は自動的に検知され即座に修正(再実行)される。
ユーザは、いつでも複数の仮想ウェアハウスを実行できる。
各ウェアハウス上で、複数のジョブが並列実行する。
ネットワークセキュリティ
仮想ウェアハウスは次の外部ネットワークアクセスを必要とする。
- クラウドサービスレイヤとの通信
- ジョブ実行時に発生する他の仮想ウェアハウスとのデータ共有
- ローカルのクラウドストレージ(diskのspill先)へのアクセス
- API Gatewayへのアクセス
Snowflakeは全ての仮想ウェアハウスからのネットワークトラフィックを信用しない。
内部サービスへのトラフィックは必ず認証済みのエンドポイントを経由する。
外部ネットワークへのトラフィックは外向きプロキシを経由し、アクセス制御ポリシーが適用される。
未認証のエンドポイントへのアクセスはブロックされ、予期しない動きはSnowflakeに報告される。
アカウント間で予期しない漏洩が起こらないように、VM、proxy、ジョブ間でやり取りされる全ての
通信が正常であることを、クラウドサービスレイヤがIPアドレスマッチングを行うことで検証する。
仮想ウェアハウスが持つ署名済みの共有シークレットを使って、仮想ウェアハウス間の全ての通信
について、発信・着信側が本当にSnowflake内部の仮想ウェアハウスであるか検証する。
そもそも仮想ウェアハウスからクラウドサービスレイヤへの通信がむちゃくちゃ多くなり、
DoS攻撃のようにならないように、通信にレートリミットがついていたりするらしい。
他には、フローログを使って何かをしているらしい。フローログって何か知らなかったので調べた。
NWインターフェース間で行き来するIPトラフィックに関する情報をキャプチャする機能。とか。
Wireshakみたいなやつだろうか。例えば、仮想ウェアハウス内のVMが知らないdestに対して
送ったIPトラフィックを見つけてforensic inspectionを行いVMを隔離するなど。
※デジタルフォレンジック。「証拠保全」みたいな使われ方をしている。
うーん..難しい…
ネットワークセキュリティと言うと、つい外部から内部(Ingress)の事かなと思っていたが、
SaaSの内部で好き放題されてしまうリスクがある気持ちを理解した。
外部ネットワークアクセスはこの気持ちの上に成立しているんだろう。
Python/Scala/Javaコードの分離
SQLみたいに出来ることが制限されている言語とは違い、何でもできるJava/Python/Scalaで
UDFやプロシージャを書くことはセキュリティ面でリスクがいっぱい。
これらの言語で書いた処理は、パフォーマンスの観点で、ジョブの他の処理と同じVM上で動く。
マルチテナント環境上で(処理を?)分離するために(前述のように再利用できない)VMを使用する
のに加え、cgroups, namespaces, secomp, eBPF, chrootのようなLinuxカーネル
の要素を使ったセキュアなサンドボックスを提供することで、ジョブに割り当たったスコープの外の
情報にアクセスしたり、処理がSnowflakeの他の機能に影響したりしないようにしている。
(これらは前述されている。それぞれうっすら調べてみた。こういう風に作るんだなぁと面白い)
Java/Python/Scalaで書かれた各ジョブには、実行用に新たにサンドボックスが割り当てられる。
コードの実行に最低限必要なread-onlyのソフトウエアが用意される。
サンドボックス用のchrootが用意され(/より上に行けない)、その下には書き込み可能ディレクトリが
いくつかあるだけ。ジョブはそこで処理を行う。read-onlyなディレクトリがマウントされて、
JavaのJARパッケージ、Pythonパッケージや、データファイルはそこで共有される。
サンドボックス内のジョブ(のリソースを使用するプロセス)はcgroupが設定され、
使用メモリ、CPU使用量、PID使用量(プロセス数?)が制限される。
マルチプロセッサユースケース(マルチスレッド化してプロセス内で処理を並列化する話?)のため
スレッド生成がサポートされる。
さらに、許可リスト(IPC,Inter Process Communicationに関するリソースを隔離する仕組み=
IPC Namespace、eBPF,extended Berkley Packet Filter=カーネル内で発生した
イベントで駆動する処理を安全・簡単に組み込む仕組みによって、予め許可していないartifacts
がサンドボックスの外に接続するUNIXソケットを開けないようにする)によるネットワークアクセスの
制限、process namespaceによるVM上の他のプロセスを見えなくする制限、
seccomp(子プロセスのフォーク、実行可能プログラムの実行)によるカーネルAPIの不必要な
実行の回避が行われる。脅威検知のためptraceがシステムコールを管理する。
ジョブが完了した後、VM上の環境のもろもろの解放、開いたソケットのクローズ、
クレデンシャルの削除、ローカルキャッシュ、一時ファイル、ログの削除が行われる。
追加の多層防御手段?(defense-in-depth measure?)として、規定時間内に終了しなかった
Python/Job/Scalaコードを実行するプロセスに対して、監視プロセスがkillシグナルを送る。
サンドボックス外に離脱したり、攻撃者が仮想ウェアハウス上のVMにプロセスを残したり
ルートキットを配置する未知のリスクに備えて、Python/Java/Scalaコードを実行したVMは
「実行不可」としてマークされる。仮想ウェアハウスのスケジューリングや起動済みVMをプールする
仕組みの上で、Python/Java/Scalaコードを実行したVMが異なるアカウント・ユーザに
割り当てられると、アカウント間情報漏洩のリスクに繋がってしまうため、異なるアカウント・ユーザに
割り当たらないようになっている。Python/Java/Scalaコードを実行するVMが作られると、
アカウント専用のVMプール入れられる。新しいVMを割り当てるときは、まずはアカウント毎の空き
プールからVMが選ばれる。
多数のゼロデイエクスプロイト(脆弱性が発見されてからパッチが当たるまでの期間の攻撃)が
連続して使用されると、サンドボックスが破られてしまうかもしれないが、それに備えた作りに
なっている。まずエクスプロイトは、ユーザアカウントで実行中のVMに存在する。このVMは、
Snowflakeサービスや、Snowflake内のローカルネットワーク上のVMから隔離されている。
攻撃者が手にしたクレデンシャルは(サンドボックスを破壊した)特定のアカウントの特定のVMに
限定され他では使用できない。
あくまで論理的な構成が書かれているだけで「コンテナ」というワードも無いし、何かチラチラとするな。
こういうのを「コンテナエスケープ」とか言うらしい。
ソフトウエア更新の管理
Snowflakeの各機能がどうやって仮想ウェアハウスにデプロイされるかについて。
(デプロイの)ワークフローにより新機能、セキュリティアップデート、機能改善が行われる。
全ての処理は自動化されていて手作業の間違いが起きないようにしている。
このリリースプロセスにおいて、単体テスト、回帰テスト、結合テスト、性能、負荷テストが行われる。
リリースプロセスは、本番の前段の環境、または本番に近い環境で行われる。
VMがフリープールに入る前に最新のパッチが当たる。VMのStartやResumeなどの操作の後に、
フリープールからVMに割り当たったり、逆にVMからフリープールに抜けたりするが、
フリープールからVMに割り当たるプロセスの一部として、VMに最新に保つための最新のバイナリが
ダウンロードされ、適用される。
Resume、Startなどのライフサイクル操作は即座に終わるように作られているが、
影響を与えないように性能要件が与えられているらしい。
SKU sizeやOSのメジャーパーションなど大きな変更の際には、未適用のVMと適用済みのVMの両方が
同時に動く状態となる。古い方は既存のジョブを実行し、新しい方は、新しいジョブを実行する。
そのようにジョブがルーティングされる。
既存のジョブを実行し終わってから、最終的に古い方は消される。
つまり、1個のウェアハウスについて、アップデートの時期を迎えると背後で(適用前後の)2個になる。
前述のようにキャッシュはVMのローカルディスクなので、もし古いウェアハウスが破棄されたとすると、
キャッシュが失われることになる。
それによりキャッシュミスが発生しパフォーマンスに影響しないように、事前に管理されているとのこと。
がんばってテストしているけれども運用環境にバグが混入することもある。
なのでアップデートをロールバックできるようになっている。
クラウドプロバイダのリージョン毎に、動作中のバイナリの背後で、古いバイナリをコピーしている。
古い方は非アクティブのままとしている。(トラフィックが発生しない?)
大規模障害に備えて、通常、新しいジョブを新しいバージョンのウェアハウスにルーティングしている
ものを古いウェアハウスにルーティングするロールバックをできるようにしている。
Issueに基づいて顧客ごとに対象を絞ったロールバックをすることもあるらしい。
顧客のワークロードはそれぞれ大分ことなるので、全員が同じ頻度でバグを踏むことはないので。
特定の顧客に対して、アップデートした一部のリリースをロールバックする、みたいなことをするらしい。
リリースノートの扱いが良い感じになっていて、こういう感じで運用されているのだな、と。
将来の機能
現在、ユーザは、ワークロードの複雑さ、処理時間、コストを考慮して適切な調整を行わないといけない。
例えば、サイズ、ウェアハウスタイプ、クラスタ数、スケーリングポリシーなど。
こういったキャパシティ調整の大変さを減らしたり無くそうとしているらしい。
microVM(例えばFirecrackerやKata Containersなど)やシステムコールのオフロードに
投資し、より強力なサンドボックス分離メカニズムを実現しようとしているらしい。
それにより、Python/Javaコードで現状ではできないことが出来るようにしたいらしい。
まとめ
Deep dive into the internals of Snowflake Virtual Warehousesを読んでみました。
たぶん公開されていない内部の仕組みの割合が多いのかなと思いましたがどうでしょうか。
正直かなり難しくて、途中、ほとんど写経状態になっている部分もありますが、
なるべく分からないところを調べながら、何を言いたいのかを趣旨の理解に努めました。
正直、知らなくても問題ないし、公開されていない以上、実際は違うかもしれないし、
将来変更されてしまうかもしれません。
1週間ぐらいかけて読んでみて、公開されている仕様を説明しやすくなった気はしました。
