




全般的に参考にできるリソースが少ない中で、公式が出すホワイトペーパーは本当に参考になる。
マルチテナントの設計方針が書かれている以下のホワイトペーパーを読んでみた。
もちろん、マルチテナント的な応用をする際に参考になりそうな話ばかりなのだが、
それだけに限らない「オブジェクト配置に関する設計の大方針」が説明されているな..と。
Design Patterns for Building Multi-Tenant Applications on Snowflake
この記事では、ホワイトペーパーを読んで気づいた何かを書き連ねてみる。
もちろんホワイトペーパーのメインはマルチテナントなのだからそう読むべきだが、
「テナント」を「グルーピングされたデータ」と仮定して追加で得られた感想を書いてみる。
英語力、文章の読解力の不足、認識違い、などなどにより誤りが多数あるかもしれませんが、
個人のメモ、ということでその点ご容赦ください。。
【目次】
- ∨オブジェクト単位で持つかテーブル内に混在させるか
- ∨1つのテーブルにテナントを混在させる (Multi-tenant table,MTT)
- ∨オブジェクトごとにテナントを配置する(Object per tenant,OPT)
- ∨アカウントごとのテナントを配置する(Account per tenant,APT)
- ∨MTT,OPT,APTまとめ
- ∨同一テーブル内でテナント同士を論理的に分離する方法
- ∨資格テーブルの保護
- ∨テナントとパーティションの割り付けとクエリ効率
- ∨フロント側から透過的にSnowflakeのSSO機能を利用する
- ∨作業用データベースを分離する
- ∨ワークロードを分離する
- ∨ユーザに適切なウェアハウスを割り当てる
- ∨OPTの特徴
- ∨複数のオブジェクトの作成を自動化する
- ∨MTTと比較したOPTにおけるユーザルーティングの重要性
- ∨MTT,OPTによるコスト最適なingest/transformation
- ∨レプリケーションはDB単位なのでOPTが適切
- ∨APTの特徴
- ∨APTの認証
- ∨評価基準:データ配置/セキュリティ観点
- ∨Snowflakeの暗号化フレームワーク
- ∨評価基準:暗号化/データ分離/保護の観点
- ∨評価基準:リソース利用、ネットワークポリシーの観点
- ∨まとめ
オブジェクト単位で持つかテーブル内に混在させるか
SnowflakeはDatabase,Schema,Tableなどのオブジェクトが割と疎に結合する構造になっている。
Snowflakeのベストプラクティスを重視すると、オブジェクト同士を疎結合したくなる欲求にかられる。
確かにZero Copy CloningやSharingなど、アーキテクチャの優位さを活用しやすいのだが、
脳死で疎結合にする前に、密結合パターンとのメリデメを一応考えた方が良いと思う。
疎結合にするということは、結合により多くの手間がかかるということだと思う。
実際にオブジェクト単位にデータを保持しようとすると、オブジェクトの数が増えすぎたり、
増えたオブジェクト間のデータを結合するのに手間を要したり、一言で書くと面倒になる。
本当にリソース単位で持つべきなのか、従来のように1つのリソースの中で論理的なグルーピングを
するのに留めた方が良いのか、ちょっと考えた方が良いと思う。
1つのテーブルにテナントを混在させる (Multi-tenant table,MTT)
複数のテナントを扱おうとしたとき、「テナントID」などを利用して1つのテーブルを共有するモデル。
何しろ、テナントがいくら増えても1つのテーブルで対処できるという簡単さがある。
そのテーブルに付随する様々なオブジェクトが増えることがない。
レコード数が増えることでクエリのパフォーマンスが落ちるのではないか、という懸念については、
ちょうど「テナントID」をクラスタキーと設定することで、テナントがマイクロパーティションに
割り当たることになり、むちゃくちゃ効率的にプルーニングが効くため、問題ない。(エアプ)
テナントが1つのテーブルを利用するためにテナント間でスキーマ定義を合わせる必要があり、
差異がある場合には、最小公倍数的な定義にする必要があり無駄が発生する。
1つのクエリで複数のテナントを横断できることがメリットでありデメリットでもある。
原理的に他のテナントのデータを触れてしまうということは便利だが確実に安全でない。
権限モデルの適用対象となるテーブルよりも小さい単位で論理的なブロックを作ると、
結果として権限モデルが関与しない場所で、列レベルセキュリティ、行アクセスポリシー、
資格テーブル等を駆使して「自前の権限設計」をしないといけなくなる。
CLONEの最小粒度はテーブル、SHAREの最小粒度はデータベースであり、
これらを積極的に使った「Snowflakeっぽい」疎結合なアーキテクチャを導入しづらい。
後述するが、複数のテナントでウェアハウスを強制的に共有してしまう。
つまりテナントごとのコンピュートコストを算出できないし、テナントごとにスケールできない。
共有することでコスト効率は良くなるため、コスト算出を分離しないで良いならメリット。
オブジェクトごとにテナントを配置する(Object per tenant,OPT)
テナントをTable単位,Schema単位,Database単位など、オブジェクト単位で分離する。
1回のSQLでオブジェクト横断的にアクセスできなくなるのがメリットでありデメリット。
何しろ、RBACによるアクセス制御が効くようになるのでセキュリティ設計が簡単になる。
オブジェクトを疎結合しましょう、というSnowflake的なデザインパターンだと思う。
箱を増やすと、それに付随するリソースを何個か作らないといけないのが常なので、
扱うテナントが増えるとすぐに管理できないくらいオブジェクト数が増える。
ホワイトペーパーには10から100数十ぐらいではないか、と書かれている。
個人的にはテナントを3個も作ったらもうIaCツールが欲しくなる。
CLONE,SHARE はOPTを前提にしているとも言える。
OPTを選択するとSnowflakeっぽいアーキテクチャにしやすい(と思う)。
アカウントごとのテナントを配置する(Account per tenant,APT)
テナントをアカウント単位で分離するという考え方。いわゆる「dedicated」な配置方式。
同一アカウント内で複数のオブジェクトに触ることは出来るが、アカウントを跨って触ることはできない。
物理的に触れない場所に分けておく方式。OPTよりもさらにグループ間の独立性を高めることができる。
リソースの共有を物理的に遮断する配置方式なので、コンピュートの効率性は良くない。
テナントごとに完全にコストを見積もることができる。
アカウントの上に「組織」の概念があるため、管理上の連続性はある。
ただ、大体のクラウドサービスと同様に、アカウントの上の管理は「取ってつけた感」があると思う。
そもそも「組織」内の複数アカウントを紐づける概念なので、
テナントがビジネス上の異なる組織であったりしたら、その時点で怪しくなる。
今回は薄く読んでおくに留める。
MTT,OPT,APTまとめ
ホワイトペーパーにPros.Cons.がまとまっていたのでざっくり意訳してみる。(テキトー…)。
特にOPT,APTのスケーラビリティが低く、用途によってMTT一択となる可能性がある。
| MTT | OPT | APT | |
|---|---|---|---|
| データモデルの特徴 |
|
|
|
| スケーラビリティ |
|
|
|
| セキュリティ的な何か |
|
|
|
| 備考 | 必ずコンピュートを共有することになる。結果としてコストが浮くし運用が楽になる。 | 要件次第でグループ間の結合度を自由に決められる。つまり、コンピュートを共有するか否かを決められる。共有すればコストが浮くがグループ間の連携に際して考えないといけないことが増える。 | RDBMSを使ったレガシープラットフォームをリプラットする際に親和性が高いのではないか。 |
| 欠点 |
|
|
|
MTTで考慮すべきデザインパターン集
同一テーブル内でテナント同士を論理的に分離する方法
まず、異なるテナントを同一のテーブルで認識するため、テナントの識別子を持たせる。
RBACに基づいたアクセス制限が出来ないため、アクセス制限を行う論理的な仕組みが必要となる。
ホワイトペーパーで紹介されているのは、資格テーブル(Entitlements Table)を用意するというもの。
資格テーブルに、どのユーザ、ロールがどのグループにアクセスできるか書いておき、JOINして使う。
Snowflakeにおいて、Viewは背後にある(Underlying)テーブルをViewの外から見えてしまう。
例えばSnowsightでViewの定義を見るとCREATE VIEW文の定義が見える。
Secure Viewを使用すると見えないため、Secure View上で資格テーブルとの結合を行う。
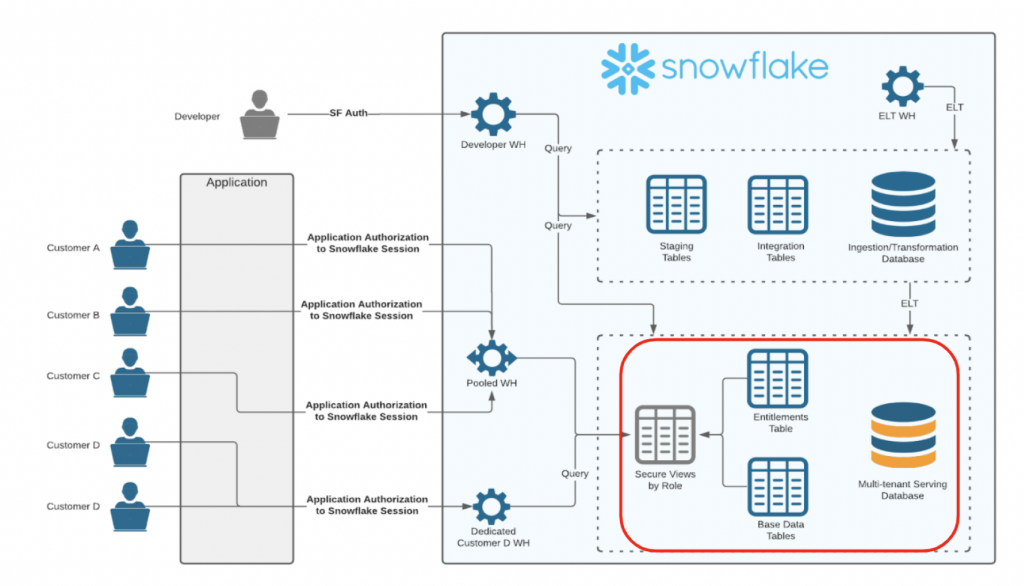
資格テーブルの保護
資格テーブルはグループを論理的に分離する上で重要で、管理を厳密にしないといけない。
誰もが触れる場所に資格テーブルがあったりすると、開発者が意図しないところで不用意に変更されてしまう場合がある。
Secure Viewと資格テーブルを異なるスキーマに配置し、開発者だけが資格テーブルを触れるように
しておけば、少なくとも非開発者が資格テーブルを変更してしまう、という事故を防げる。
例えば「ユーザが増える度にINSERT/UPDATEして資格テーブルを書き換える」ような運用をすると、
どこかでミスってガバい資格テーブルになってしまうかもしれない。
ユーザ・ロールの権限の変更により自動的に資格テーブルが更新されるような仕組みを用意しておくべき。
常に回帰テストを実施して、ガバい論理テーブルにならないよう注意すべき。

テナントとパーティションの割り付けとクエリ効率
(根拠が薄いのだが)、クラスタキーを手動設定してオレオレクラスタリングを強制したとしても、
Snowflakeが自動的に決めた(Naturalな)クラスタリングに勝てない場合が多い気がする。
要は、将来叩かれるであろうあらゆるクエリのWHERE句かJOINのON句がいかに多くのパーティションを
プルーニングするか、が大事だが、普通、そんなに期待通りプルーニングできないと思う。
テナントIDをクラスタキーとして、そのテナントのデータだけを取得する、ということは、
原理的には該当テナントのパーティション以外をプルーニングすることを保証する訳で、
これは結構期待できるのではないかと思う。(ちょっとやってみたい)
ベスプラでは、クラスタキーは2,3個程度とされていて、他に日付などを設定する。
グループの識別子をソートして並べておく。
通常、背後でSnowflakeが自動的にクラスタリングを処理してくれる(自動クラスタリング)。
もしテナント数が増加してテーブルのレコード数が増えると、自動クラスタリングの負荷が上がる。
INSERT,UPDATE等の追加変更操作をトリガとして自動クラスタリングが走るので、
頻繁に追加変更操作をするシナリオだと超絶課金されてしまうかもしれない。
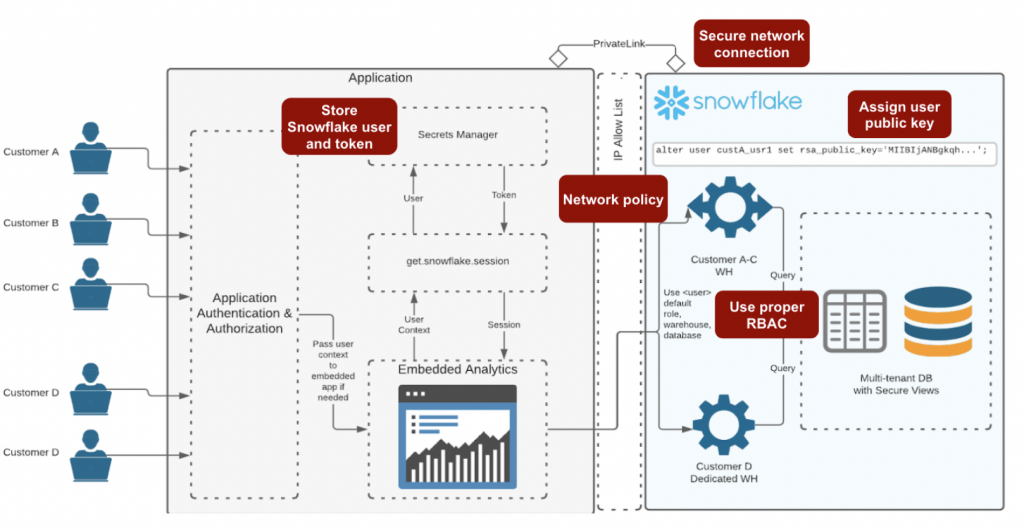
フロント側から透過的にSnowflakeのSSO機能を利用する
昔、Laravel製のWebアプリにOAuthによるSSO機能を実装したことがある。
SnowflakeはSAMLによるSSOもサポートしていて、ほぼノーコードでIdPとのSSOを実現できる。
SnowsightでSnowflakeを使う分にはポチポチ連携して終了で良いのだが、
通常、SnowflakeのフロントにBIツールなどのアプリケーションが存在し、
ユーザはフロントの認証機構を介して透過的にSnowflakeのデータにアクセスしたい。
フロント側のアプリはSnowflakeの以下の機構を利用してSSOを実現することになる。
カスタムクライアント用のSnowflake OAuth の構成
公開鍵認証方式によるOAuthアクセストークンを介したセッションへの認可が行われる。
アクセストークンに対するアクセスとセキュリティはフロント側アプリの実装に任される。
例えば、AWS Secrets Managerなどを利用することで、アプリ側が堅牢になったりする。
フロント側アプリへのログインにより、有効なアクセストークンと対応するセッションが得られ、
セッションを経由して、セッションに紐づくデータにアクセス可能となる。
Snowflake側で認可を無効にすることができる。
とはいえ、OAuthに対応したBIツールなんかでは、画面ポチポチだけで連携できるので便利。
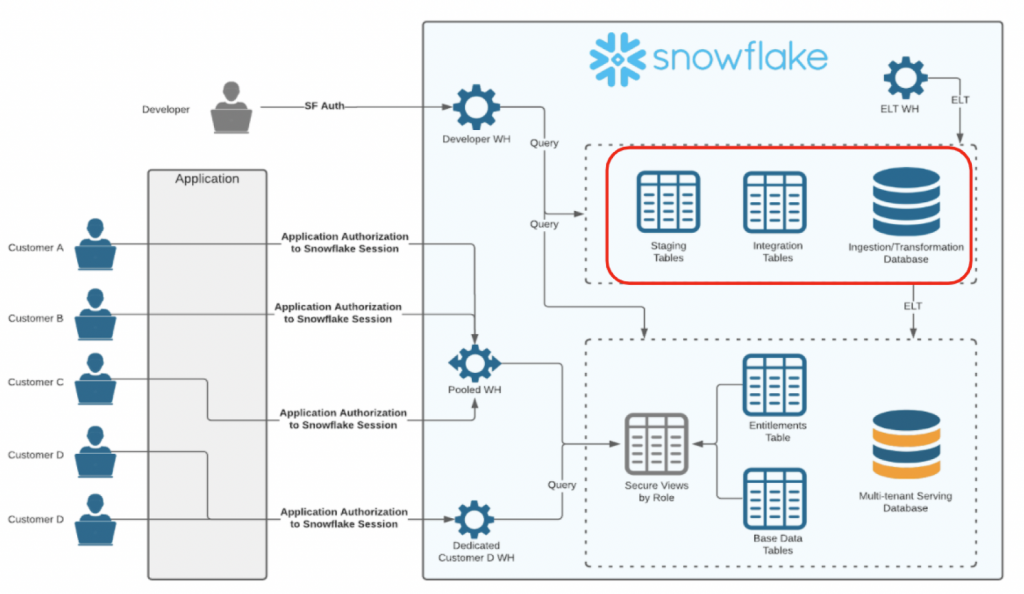
作業用データベースを分離する
RBACによるアクセス制御によって、「ここで何をすべきか」、「誰が何に触れるべきか」を定義する。
データベースを分離して権限設定することにより、これらが明確になり管理を単純化できる。
例えば、ELTの際に作成する中間テーブルなどは本体のリソースと異なり一般ユーザに開放する必要はないため、
公開用データベースとは異なる別のデータベースに作成し、別に権限設定をすべき。
開発者のみが中間テーブルなどにアクセスできる仕組みを構築できる。
ワークロードを分離する
Snowflakeの大原則は、ウェアハウスの稼働時間に対して課金されること。
ウェアハウスのサイズを大きくすることでワークロードの処理時間が短くなるのであれば、
大きなウェアハウスでワークロードを短時間に終わらすことが目指すところ。
スケールアップにだけ目が行って稼働時間の短縮を忘れるとコスト的に酷い目に合う。
例えば、BIのような用途だと、小さなウェアハウスを予測可能な時間帯で回すことになる。
一方、AdHocな用途だと、大きなウェアハウスを予測不可能なタイミングで回すことになる。
これらのワークロードを1つのウェアハウスに盛ると、大きなウェアハウスを長時間稼働させてしまう。
「小サイズ高稼働」と「大サイズ低稼働」を分けておけば、大サイズは高稼働しないので、
結果的に安くなる。
マルチテナント的には、テナントにデフォルトで共有ウェアハウスを割り当てておき、
オプションで(有料で)占有ウェアハウスを割り当てる、なんていうパターンもある。
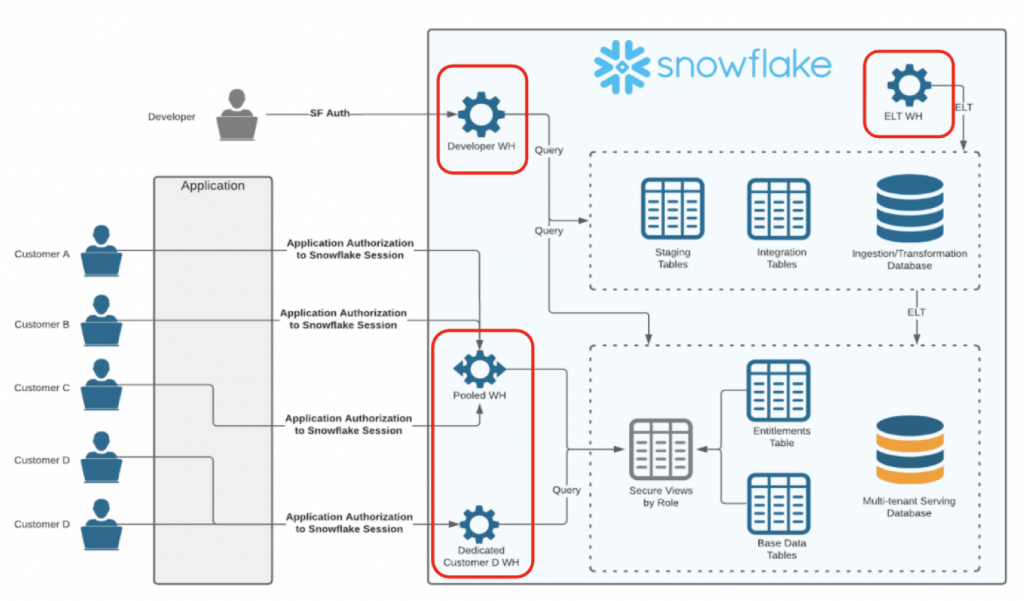
ユーザに適切なウェアハウスを割り当てる
複数のウェアハウスを使用・操作できるようにロールのアクセス制御を行いユーザにアタッチすると、
ユーザはセッション内にウエアハウスを選択できるようになる。
ユーザに対してデフォルトのウェアハウスを設定することで、より適切なルーティングが可能となる。
(ロールに対してデフォルトのウェアハウスを設定することはできない。あくまでユーザに設定する。)
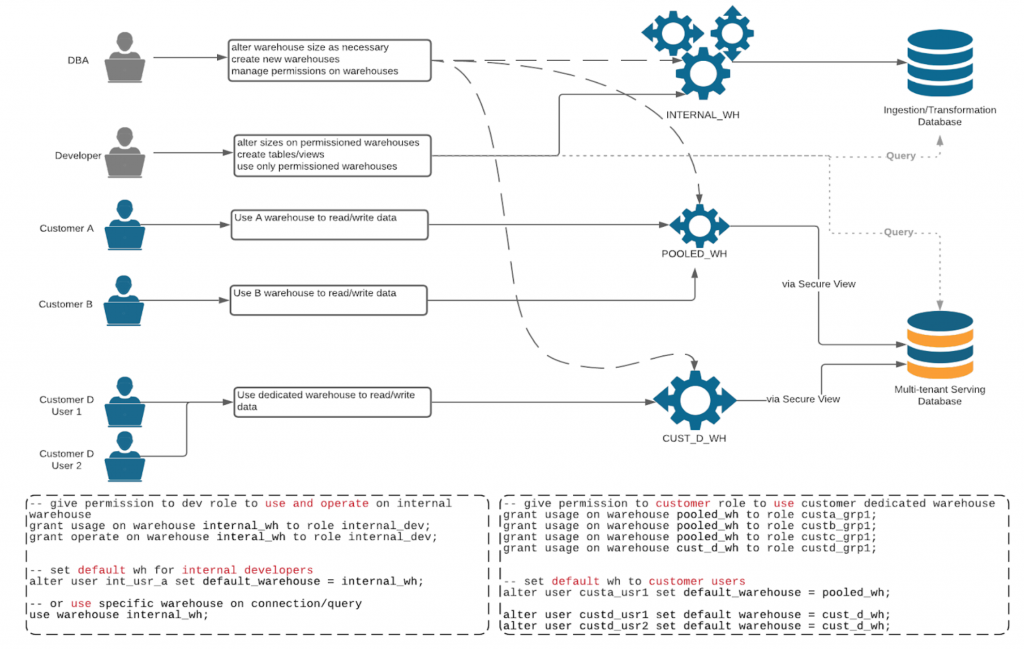
OPTで考慮すべきデザインパターン集
OPTの特徴
テナントをオブジェクト毎に分離する方法。オブジェクトを疎結合する大方針にあったやり方。
最も簡単に綺麗に分離できる。
データベース毎か、スキーマ毎か、テーブル毎か、パイプラインが満たす要件、開発のライフサイクル、
テナント毎のデータにどれだけ一貫性があるか、などにより選択する。
また、テナント数はどの程度か、テナントは何個のテーブルを使用するか、
CLONEするか、レプリケーションするか、など多くのことを想定しないといけない。
CLONEはデータベース、スキーマ、テーブルの各層で効くが、レプリケーションはDB単位だから、
その観点でオブジェクトを選択しないといけない。
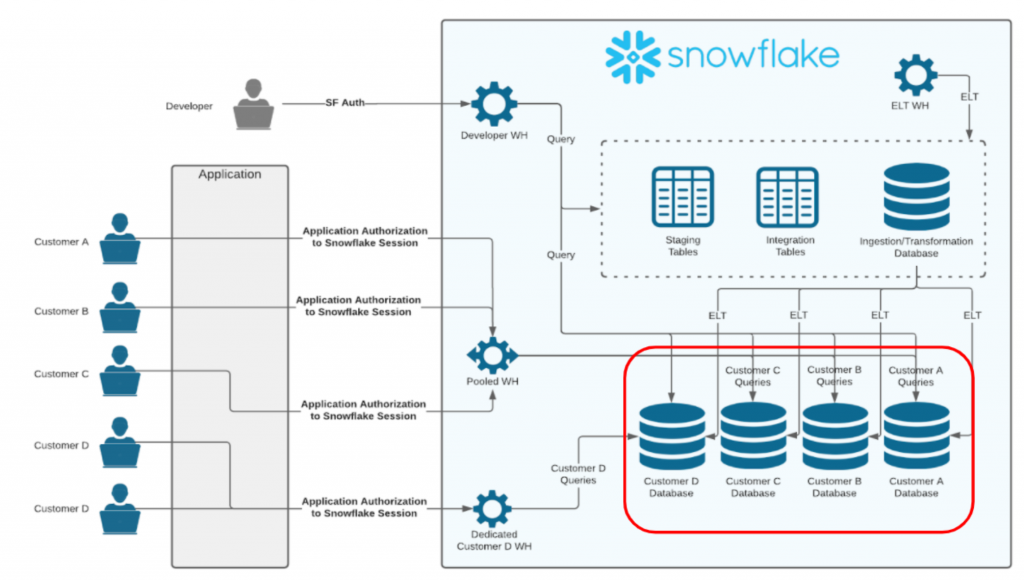
複数のオブジェクトの作成を自動化する
テナントが増えると、そのオブジェクトに関係するアクセス権などを維持するオブジェクトを追加する
必要が発生する。それぞれのテナントに個別の設定もあれば一貫性を保つべきものもある。
テナントが少ないうちは手でポチポチやっていても良いが、多くなってくると大変になる。
そういった背景があって、リソース作成を自動化したいという欲求が発生する。
外部のいろいろなIaCツールを使って自動化すると便利になる。
この辺り、昔Webアプリを書いていた頃お世話になっていた何かと久々に再会。
要はアプリケーション開発の一部としてSnowflakeリソースを一貫性をもって構築する。
マイグレーションツールのFlywayがSnowflake対応している。
Flywayを使ってスキーマ定義の一貫性を保てる。
(対応している範囲であれば)Terraformを使ってリソースの一貫性を保てる。
MTTと比較したOPTにおけるユーザルーティングの重要性
Authenticating and authorizingの節、読解が難しい。
ユーザを正しいデータベース、ウェアハウスに繋ぐ方法はMTTと同様だがMTTよりも重要である、
なぜMTTの時よりも重要になるのか、は、MTTと比較して文脈(context)が異なるから、とのこと。
MTTの場合、オブジェクトを共有するため、アクセス権はオブジェクトへのルーティングではなく、
オブジェクト内の資格テーブルが決定する一方で、OPTの場合は、まさにアクセス権そのものになるから、
とか、オブジェクトごとにテナントを分離するのだから、ユーザを誤ったテナントに誘導してはならない、
とか、そういうことを言いたいのだと思う。
重要な位置がMTTとOPTで異なりOPTの場合は重要、ということだろう。
MTT,OPTによるコスト最適なingest/transformation
ELTLのingest/transformation用テーブルの配置方法によってコストが変わる。
しばしば、1つのオブジェクトにワークロードを詰める場合、個別のオブジェクトに分散させる
よりも低コストである。例えば、複数テナントを分離した各テナント毎に
ELTL ingest/transformation用テーブルを用意し、それぞれ別々にパイプラインを
走らせるよりも、共通のテーブルに対して1つのパイプラインを走らせる方が
低いコストで済む。(理由が明示されていないが、感覚的にはオブジェクトごとにクエリが
分割されてしまうことでクエリの実行回数が増加し、結果として長い時間ウェアハウスが
稼働していまうからだと考える)
いろいろ組み合わせが考えられる。OPTとMTTを組み合わせたhybrid構造によりコストと
機能を最適化する。つまり、ingest/transformationを共通オブジェクトで行い、その後、
各テナント毎のオブジェクトに展開するか、そのまま共通のデータベースに展開するかを選ぶと良い。
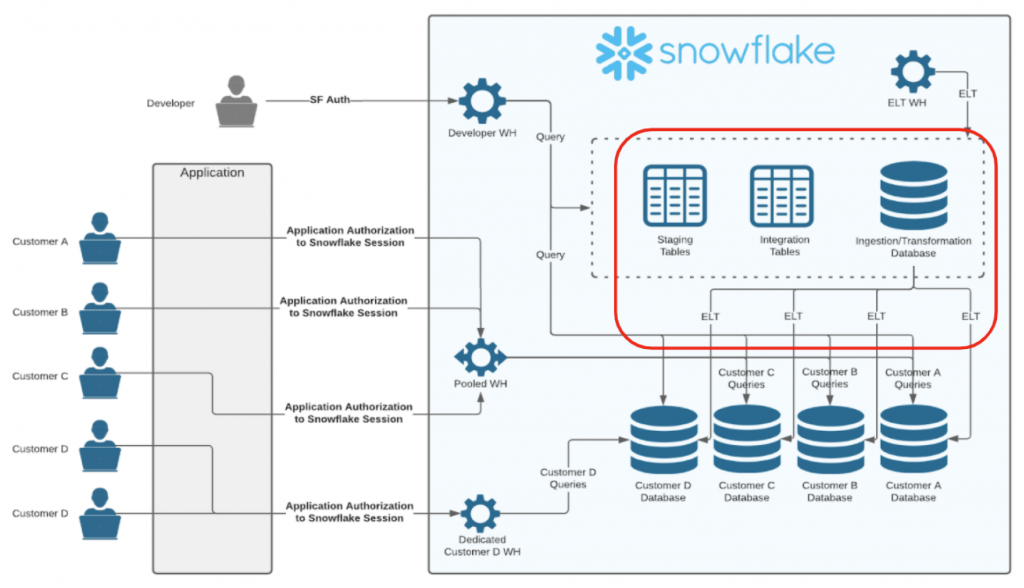
レプリケーションはDB単位なのでOPTが適切
レプリケーションはデータベース単位なので、テナントがデータベース内のリソースを
共有してしまっていると、個別のテナントを選択してレプリケーションすることが難しくなる。
そういった用途があるのであればOPTとしてデータベース単位にテナントを分けるべき。
APTの特徴
1つのテナント毎に1つのSnowflakeアカウント、ウェアハウス、1つのデータベースを用意する。
ただし、アカウントを跨いで出来ることは限られるため、どうしても例外が発生してしまう。
基本的には、アカウント内に存在するデータベースに対してアカウント内のウェアハウスで処理するが、
共通データベースのingestion/transformationデータをSHAREして持ってきたり、
持ってきたデータに追加のELTLをかけたりするために、追加のウェアハウスが必要となる場合がある。
アカウントを跨ってウェアハウスを共有することはできないので、APTの場合最もコストがかかる。
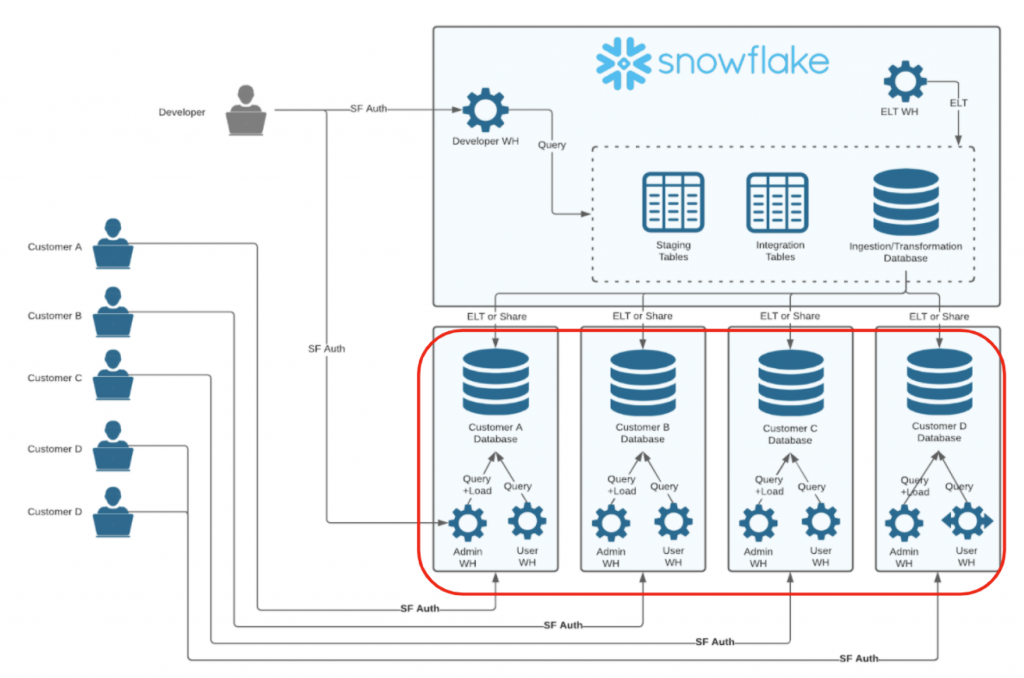
APTで考慮すべきデザインパターン集
APTの認証
フロント側の認証の方法はMTT,OPTと同じものが大体機能する。
APTはアカウント毎にログインURLが異なる。ユーザとアカウントが1対1対応するため、
フロント側を介さずにユーザが直接Snowflakeアカウントにログインすることも可能となる。
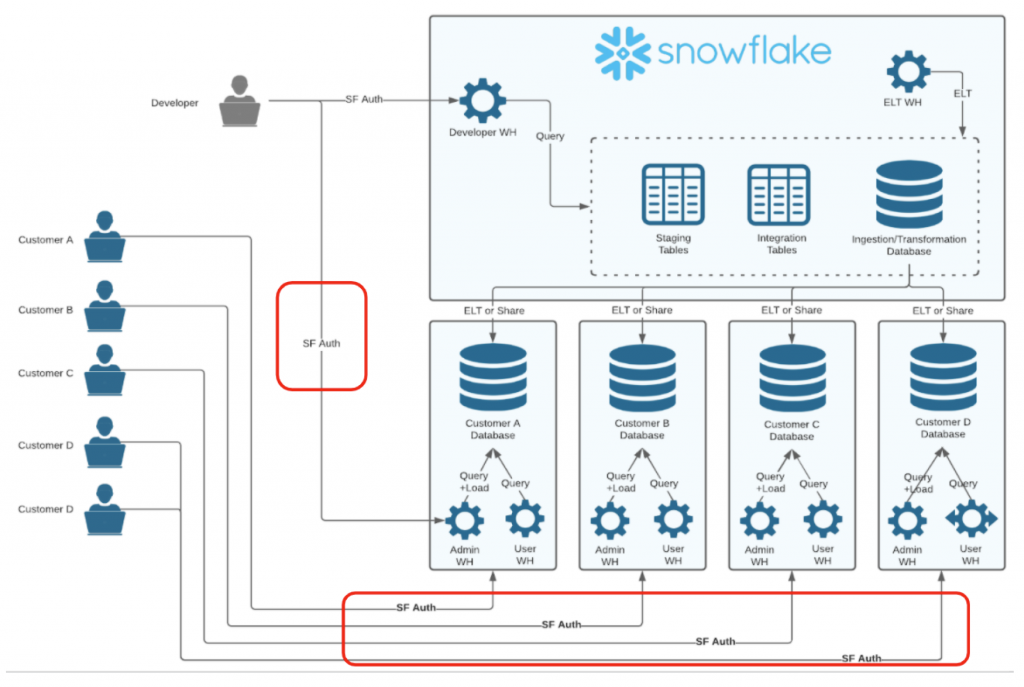
評価
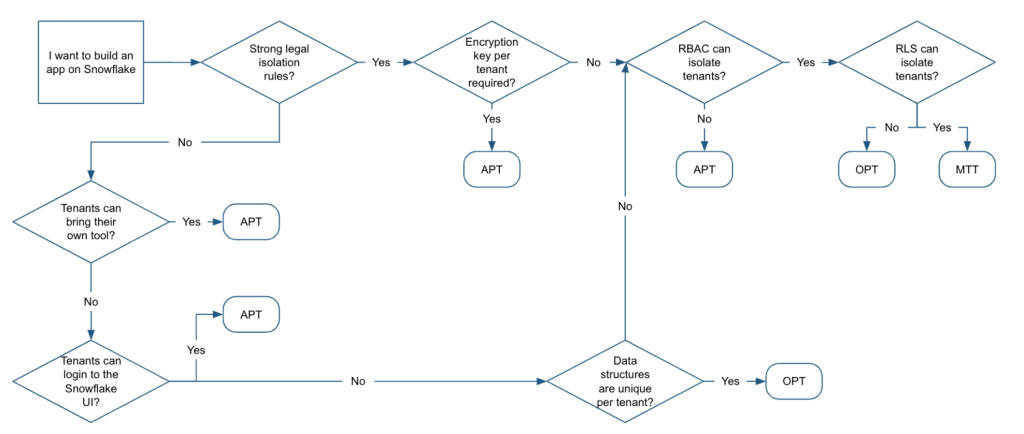
評価基準:データ配置/セキュリティ観点
3つのモデルを評価すべきだが、SnowflakeはMTTから評価をスタートすることを推奨している。
つまり、最初にMTTが機能するか、そうでないなら何故かを評価すべき。
データの配置方法・セキュリティ観点での評価チャートは以下の観点に依存する。
- データが配置・暗号化に関する契約上の責任
- データが配置・暗号化に関する規制上の責任
- データの配置・暗号化に関する情報セキュリティ基準
- アプリケーション所有者がRBACの強制をどう見ているか
- アプリケーション所有者が資格テーブルに対する行レベルセキュリティをどう見ているか
- 顧客のアプリケーションへのアクセス方法
- テナント間でテーブルスキーマ等のシェイプがどれだけ近いか
MTTを軸に、以下のチャートを見て判断する。
Snowflakeの暗号化フレームワーク
Snowflakeの暗号化体系について詳細を知らなかったので一旦まとめてみる。
暗号化キーの階層モデル
Snowflakeの大前提の1つに、すべてのデータはat restで暗号化される、という点がある。
セキュリティ標準に基づいてAES256ビット暗号化を行う。その際、暗号化キーを管理する。
暗号化キーの管理方法が厄介なのだが、独自の管理を行うため基本的にユーザの手間はない。
暗号化キー管理については以下。
Snowflakeの暗号化キー管理を理解する
Snowflakeにおいて、暗号化キーは階層モデルに基づいて暗号化される。
暗号化キーは以下の4つのレイヤから構成され、各レイヤと対応するキーが用意される。
上位レイヤのキーが下位レイヤのキーを暗号化する。
もちろん、各レイヤの暗号化キーは各レイヤのオブジェクトの暗号化に使われる。
1. ルートレイヤ (Root Keys)
2. アカウントレイヤ (Account Master Keys)
3. テーブルレイヤ (Table Master Keys)
4. ファイルレイヤ (File Keys)
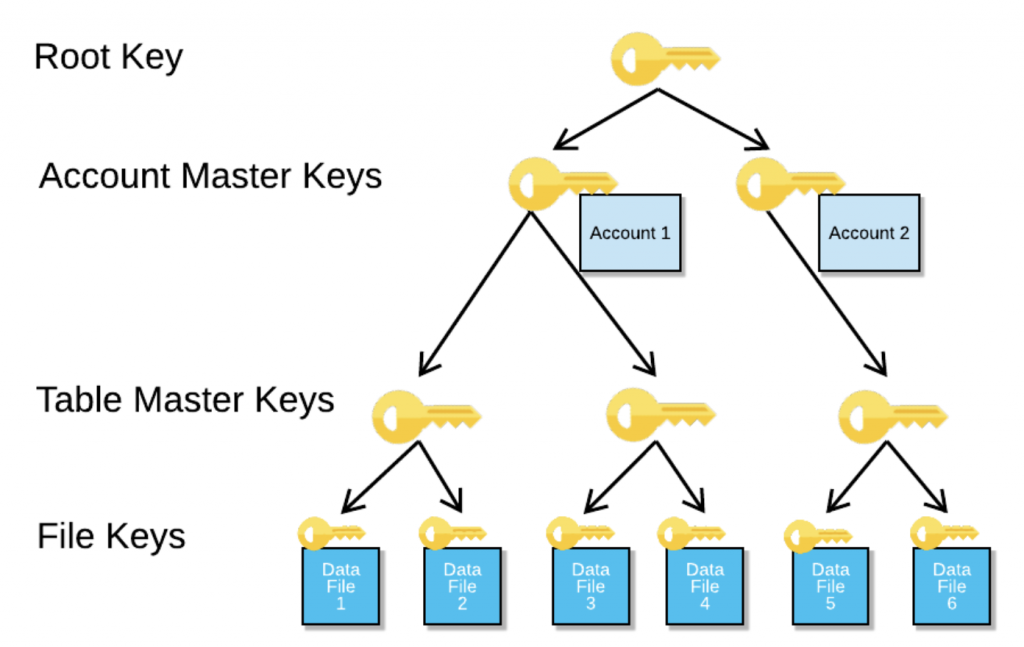
下のレイヤにおいて、より狭い範囲を適用範囲とすることとなる。
ルートキーだけだと巨大な範囲を1つのキーで暗号化せざるを得ないが、
細分化しておくことで、各暗号化キーが対象とする範囲を狭くすることができる。
アカウントレベルで、アカウント毎に暗号化キーが用意されることに注意する。
アカウント毎に異なる暗号化キーによりAES256暗号化が行われ分離される。
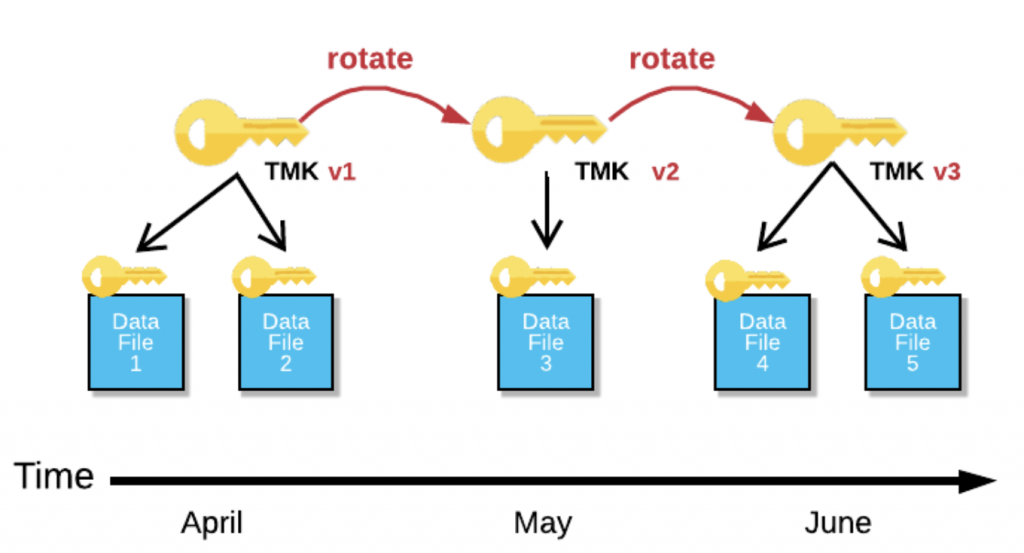
暗号化キーのローテーション
どれだけ堅牢に暗号化キーを管理していたとしても、長時間晒されることはリスク。
なので、定期的に暗号化キーをローテーションしよう、という発想になる。
Snowflakeにおいて、各暗号化キーは30日ごとに自動的に更新される。
常に最新の暗号化キーで暗号化が行われ、古くなったキーは復号にのみ使われる。
こうすることで、同じ暗号化キーの有効期限を限定できるようになる。
Tri-secret Security
Snowflakeをホストするプラットフォームで顧客が管理する暗号化キーを管理する。
Snowflakeが用意する暗号化キーと顧客管理の暗号化キーをセットで使って
複合マスターキーを作る。
複合マスターキーはアカウントレイヤのマスターキーとして使われ、
階層内の(テーブル、ファイルの)暗号化キーをラップする。
(暗号化キーをさらに暗号化するのであって、生データを暗号化したりはしない。)
複合マスターキー内の顧客管理キーを無効化すると、複合マスターキーが関与する
範囲のデータを復号できなくなり、一段セキュリティレベルが上がる。
顧客管理キーは”アカウントレベル”のみ。テーブル、ファイルレベルは無い。
“Tri”ということで3つの要素からなるセキュリティフレームワークなのだが、
その構成は以下。この項は 2つ目の”顧客管理キー組み入れ”。
1. Snowflakeの暗号化フレームワーク
2. 顧客管理キー組み入れ
3. Snowflakeの組み込みユーザ認証
評価基準:暗号化/データ分離/保護の観点
暗号化/データ分離/保護の観点でマルチテナントを選ぶケースもある。
クラウド上でテナントを論理的に分離している訳ではない、という原理があり、
その上で、Tri-secretセキュリティにより暗号レベルで分離している。
MTT<OPT<<APTの順にその分離の強度が上がっていく。どこに落ち着かせるか。
- Tri-secretの顧客管理キー組み入れでアップデートされる暗号化キーはアカウントレベルのみ
- 暗号化キーの階層管理はアカウント、テーブル、ファイルの各レイヤで効き、アカウント間のアクセスを防ぐ。ただしShareした場合は別
- Snowflakeは複数のテナントをクラウド上で管理する。物理的に分離している訳ではないが異なる暗号化キーにより暗号レベルで分離する
- データベースやスキーマは論理的な区分である。物理的にデータを分離している訳ではない
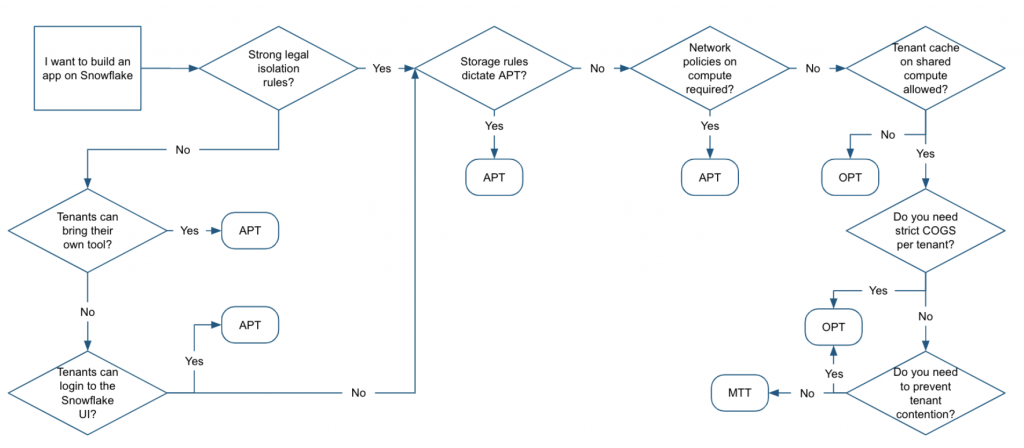
以下の観点で決めていく。
- ネットワークポリシー要件。MTT,OPTのように論理的なユーザレベルの制御で良いか。またはAPTのようにアカウントレベルの個別の制御が必要か
- (APTのように)テナント毎に仮想ウェアハウスを分離し、ウェアハウスキャッシュに生成されるデータを分離する必要があるか
- テナント毎のコスト管理をどのように行い顧客に課金するか。もしウェアハウスのコンピュートをテナントで共有する場合、経験的で不正確な方法でコスト管理をする必要がある
- 顧客はどのような方法でSnowflakeにアクセスするか
- どれぐらい多くのテナントが同時に1つのウェアハウスを使用するか
評価基準:リソース利用、ネットワークポリシーの観点
最後の項目。結構際どいことが書いてある。仮想ウェアハウスキャッシュはキャッシュが作られたときのRBAC,SecureViewも再利用するらしいw
- IPアドレスによるネットワークアクセス制御はアカウント単位のユーザレベル。(OPT以下では全テナント共有となる)
- 仮想ウェアハウスキャッシュは、それ以降に発生するクエリにおいて、クエリの一部または全部で再利用される。RBACまたはSecureViewは再利用される
- Snowflakeのコストはウェアハウス単位で課金される。複数テナントがウェアハウスを共有した場合、クエリ単位、ユーザ単位、テナント単位のコスト見積もりを正確に出せない
- ユーザ・テナント単位にウェアハウスの使用制限をつけることはできない
まとめ
Design Patterns for Building Multi-Tenant Applications on Snowflakeを読んでみて、
思ったところを書いてみた。当然、マルチテナントの設計方針について詳細に書かれているが、それ以上に、
「似て非なるデータをどうやって持つか」という、重要な観点がチラチラ気になる内容だった。
ということで1万字越えの記事は終了。
