




どのようにテーブル設計するとパフォーマンスを得られるか.
公式がベストプラクティスを用意している.
Redshiftのベストプラクティスが先にあってER図が後なのか、
ER図に対してベストプラクティスを適用するのか、
実際は行ったり来たりするようなイメージ.
ER図とは別に何を考慮すべきなのか読み進めていく.
ソートキー
テーブル作成時に1つ以上の列をソートキーとして設定できる.
設定するとソートキーに準じたソート順でディスクに格納される.
ソートキーに関するベストプラクティスは以下の通り.
- 最新のデータを得たい場合はタイムスタンプ列をソートキーにする.
- 1つの列に対してwhere句による範囲指定or等価指定をおこなう場合はその列をソートキーにする.
- ディメンションテーブルを頻繁に結合する場合は結合キーをソートキーにする.
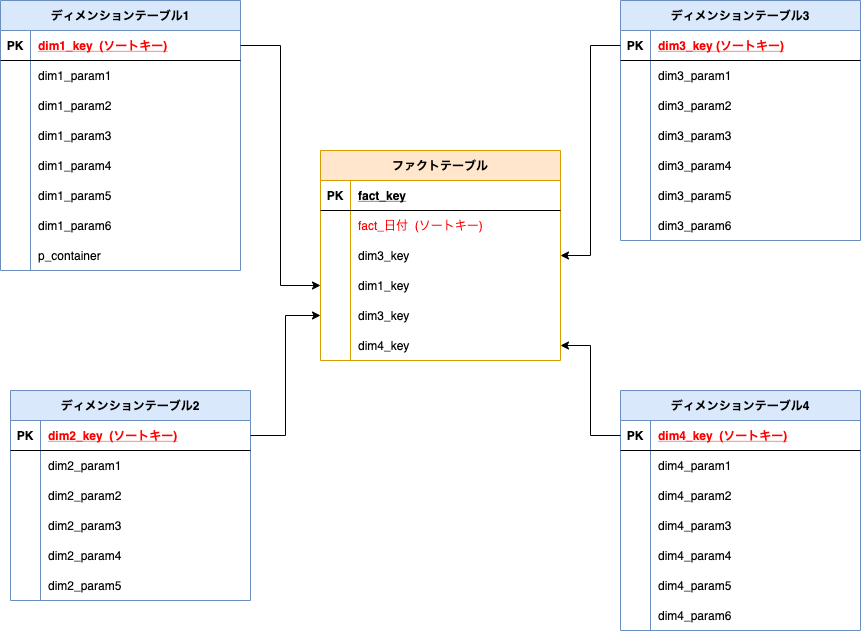
ファクトテーブルを中心にディメンションテーブルが4つある構造があるとする.
ファクトテーブルにはディメンションテーブルのPKが入り関連している.
また、ファクトテーブルに日付カラムがあり、常に最新のレコードが欲しいとする.
ベストプラクティスによると、
各テーブルの各カラムに以下のようにソートキーを設定する.
分散スタイル
クエリの実行を複数のクラスタ(コンピューティングノード、スライス)で実行するために、
それらに1)データを配信して 2)計算させて 3)結合、集計する というステップが必要になる。
最後のステップ3を達成するために、データの再び配ることが必要となる。
全体として最適となるように、1),2),3)の効率を高める必要があるが、
あらゆるデータ、条件について同じ戦略で最高の効率を得ることはできず、
設計者が戦略を指定するパラメタとなっている。
この戦略を分散スタイルと呼んでいる. 分散スタイルとして以下の3通りが用意されている.
各々だけ読むとさっぱり意味がわからないが、結局のところ再分散のコストをいかに減らすか、
というところに着目すると合点がいく.
- EVEN 分散
- 特定の列に含まれている値と関係なくラウンドロビンで複数のスライス間で行を分散させる.
- テーブルが結合に関与していない場合や、キー分散、ALL分散のどちらが良いかわからない場合に指定する.
- キー分散
- キー分散のキーとは結合キーのこと.
- 特定の列に含まれている値に従って複数のスライスに行を分散させる.キーが同じということは「同じデータ」であり「同じデータ」達を同じスライスに分散させる意味がある.
- 共通の列からの一致する値が同じスライスにまとめられるよう努力する.
- ALL 分散
- テーブル全体のコピーが全てのノードに分散される.
- EVEN分散、キー分散によってテーブルの一部が各ノードに配置されているときにALL分散を行うことでテーブルが関与しているあらゆる結合で全ての行が確実にコロケーションされる.
- 何が嬉しいのかわかりづらいが、EVEN分散やキー分散では、クエリ実行に伴って、再び必要なデータをコピーする(再分散する)必要が発生する可能性が生じる.ALL分散であればその可能性がなくなる.
- AUTO 分散 (デフォルト)
- テーブルデータのサイズに基づいて最適な分散スタイルを割り当てる.
- まず小さなテーブルにALL分散を設定し,テーブルが大きくなるとEVEN分散に切り替える.
- 分散スタイルを明示的に設定しないとAUTO分散になる.
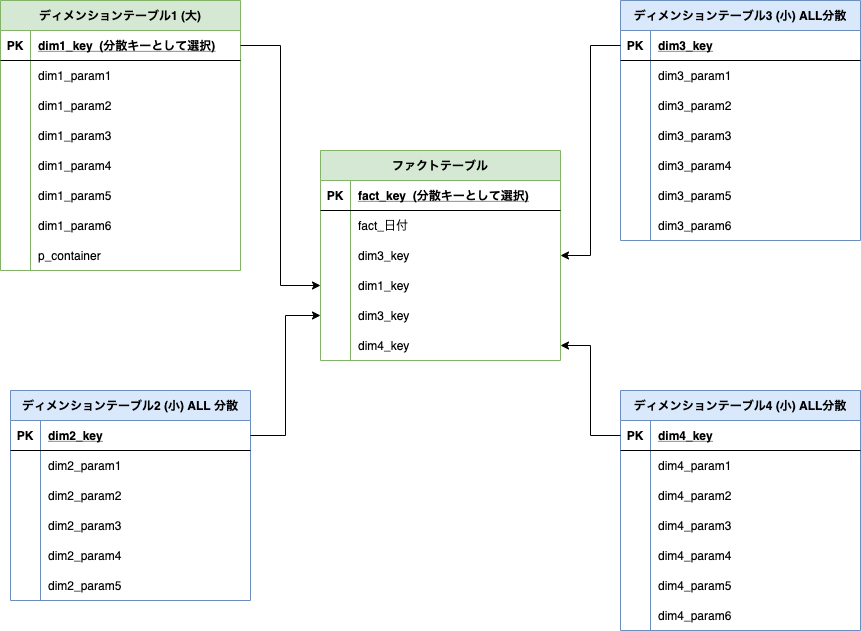
まず、ファクトテーブル関連する1つのテーブルの共通の列に基づいて分散させる.
関連するテーブルの選び方の観点は大きさで最もレコード数が大きいテーブルを選択する.
以下の構造では、ファクトテーブルとディメンションテーブル1が
dim1_keyというキーを使って結合している.
そこで, ファクトテーブルのdim1_key、ディメンションテーブル1のdim1_keyを分散キーとして採用する.(緑)
ここまでで、dim1_keyの値が一致するレコードが同じスライスにコロケーションされる.
キー分散に使うキーは1組のみ.
残りのテーブルについてはEVEN分散かALL分散を用いる. 選び方は上記の通り.
テーブルのサイズが小さいのであれば、ALL分散により再分配の可能性がなくなり選びやすい.
圧縮エンコーディング
通常のRDBのように行方向の固まりを記録する場合、各列の値は型や値の傾向がまちまちであるため、
一様に圧縮しようとしても高い圧縮率を得られない.
対して、列方向の固まりを記録する場合、各列の型は同じだし値の傾向が似ていることが多いため、
高い圧縮率を得られる可能性がある. ただし、値の傾向により圧縮アルゴリズムを選択する必要がある.
公式で挙げられているアルゴリズム.
結局試してみないとわからない、というのはある.
(Zstandard強すぎないか?)
- raw エンコード
- 圧縮をおこなわない.
- ソートキーが設定されているときはrawエンコードが設定される
- BOOLEAN、REAL,DOUBLE PRECISION型もraw.
- AZ64 エンコード
- Amazon 独自の圧縮エンコードアルゴリズム
- より小さなデータ値のグループを圧縮し、並列処理に SIMD (Single Instruction Multiple Data) 命令を使用する
- 数値、日付、および時刻データ型のストレージを大幅に節約する
- バイトディクショナリエンコード
- バイトディクショナリエンコード
- ディスク上の列値のブロックごとに、一意の値の個別のディクショナリを作成する
- 列に含まれる一意の値の数が制限されている場合に非常に効果的
- 列のデータドメインが一意の値 256 個未満である場合に最適
- CHAR 列に長い文字列が含まれる場合に特に空間効率が高まる
- VARCHAR 列に対しては、LZO などの BYTEDICT 以外のエンコードを使用する
- デルタエンコード
- 列内の連続する値間の差を記録することにより、データを圧縮
- 日時列にとって非常に有用
- 差が小さいときに特に有用
- LZO エンコード
- 非常に長い文字列を格納する CHAR および VARCHAR 列、特に製品説明、ユーザーコメント、JSON 文字列などの自由形式テキストに適している
- Mostly エンコード
- 列のデータ型が、格納された大部分の値で必要なサイズより大きい場合に有用.
- たとえば、INT2 列などの 16 ビット列を 8 ビットストレージに圧縮できる
- ランレングスエンコード
- 連続して繰り返される値を、値と連続発生数 (実行の長さ) から成るトークンに置き換える
- データ値が連続して繰り返されることが多いテーブルに最適
- たとえば、テーブルがこれらの値でソートされている場合など
- Text255 および Text32k エンコード
- 同じ単語が頻繁に出現する VARCHAR 列を圧縮する場合に有用
- Zstandard エンコード
- 多様なデータセット間で非常にパフォーマンスのいい高圧縮比率を提供
- 製品説明、ユーザーのコメント、ログ、JSON 文字列など、長さがさまざまな文字列を保存する CHAR および VARCHAR 列に対して有用
圧縮エンコーディングをテストするためには、
各アルゴリズムで差が出るように大量のデータを用意する必要がある.
公式には、テストするために大量のデータを用意することは難しいので
デカルト積ででっち上げる手法が案内されている.
例えば、こんな感じにデータをでっちあげる.
create table cartesian_venue(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer
);
insert into cartesian_venue
select venueid, venuename, venuecity, venuestate, venueseats
from venue, listing;
このうち、venunameに対して各エンコーディングアルゴリズムを適用して格納するデータを作る.
create table encodingvenue (
venueraw varchar(100) encode raw,
venuebytedict varchar(100) encode bytedict,
venuelzo varchar(100) encode lzo,
venuerunlength varchar(100) encode runlength,
venuetext255 varchar(100) encode text255,
venuetext32k varchar(100) encode text32k,
venuezstd varchar(100) encode zstd);
insert into encodingvenue
select venuename as venueraw, venuename as venuebytedict, venuename as venuelzo, venuename as venuerunlength, venuename as venuetext32k, venuename as venuetext255,
venuename as venuezstd
from cartesian_venue;
知りたいことは、encodingvenueの各列で実際に使われているディスク容量.
以下のようにして各列で使用される1 MBのディスク ブロック数を比較するらしい.
rawが203に対してBYTEDICTが10. つまりBYTEDICTにより20:1の圧縮率を得られた例.
select col, max(blocknum)
from stv_blocklist b, stv_tbl_perm p
where (b.tbl=p.id) and name ='encodingvenue'
and col < 7
group by name, col
order by col;
col | max
-----+-----
0 | 203
1 | 10
2 | 22
3 | 204
4 | 56
5 | 72
6 | 20
(7 rows)
まとめ
公式のベストプラクティスを追ってみた.
面倒だけれども結構力技で出来ているなという印象.
与えられたスタースキーマからある程度決まったやり方でパラメタを選択できそう.
実データでやったら迷うことは必至w
ソートキーと分散スタイルの選択は分散コストに影響する.
圧縮エンコーディングの選択はディスクストレージに影響する.
理解したら実際に試行錯誤していくしかないイメージ.
