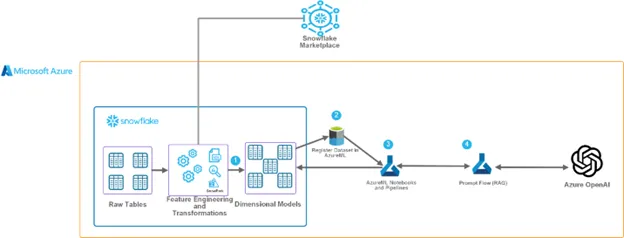
コンピューティング
パフォーマンス
シンプルに面白かったです。器用に計画されるのだなと。以前これにハマっていてその時適用されていたら解決していたのかもしれない。compiler staticではなくadaptive…のくだり興味深い。。
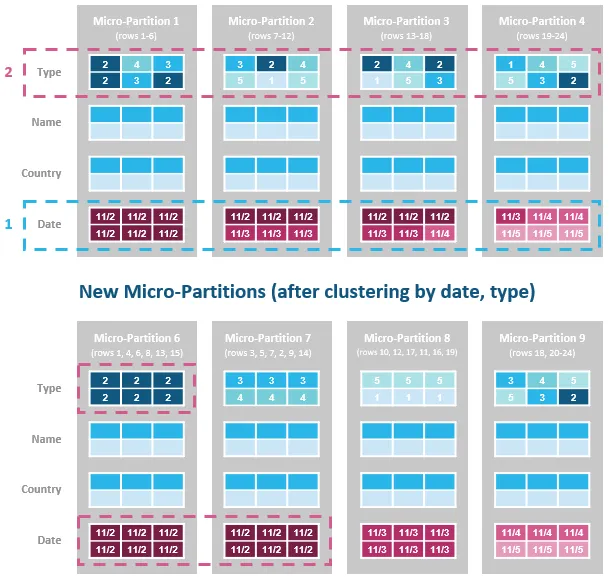
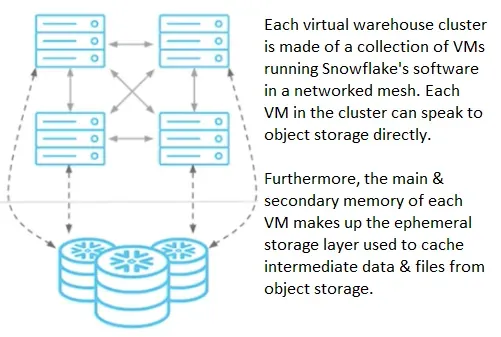
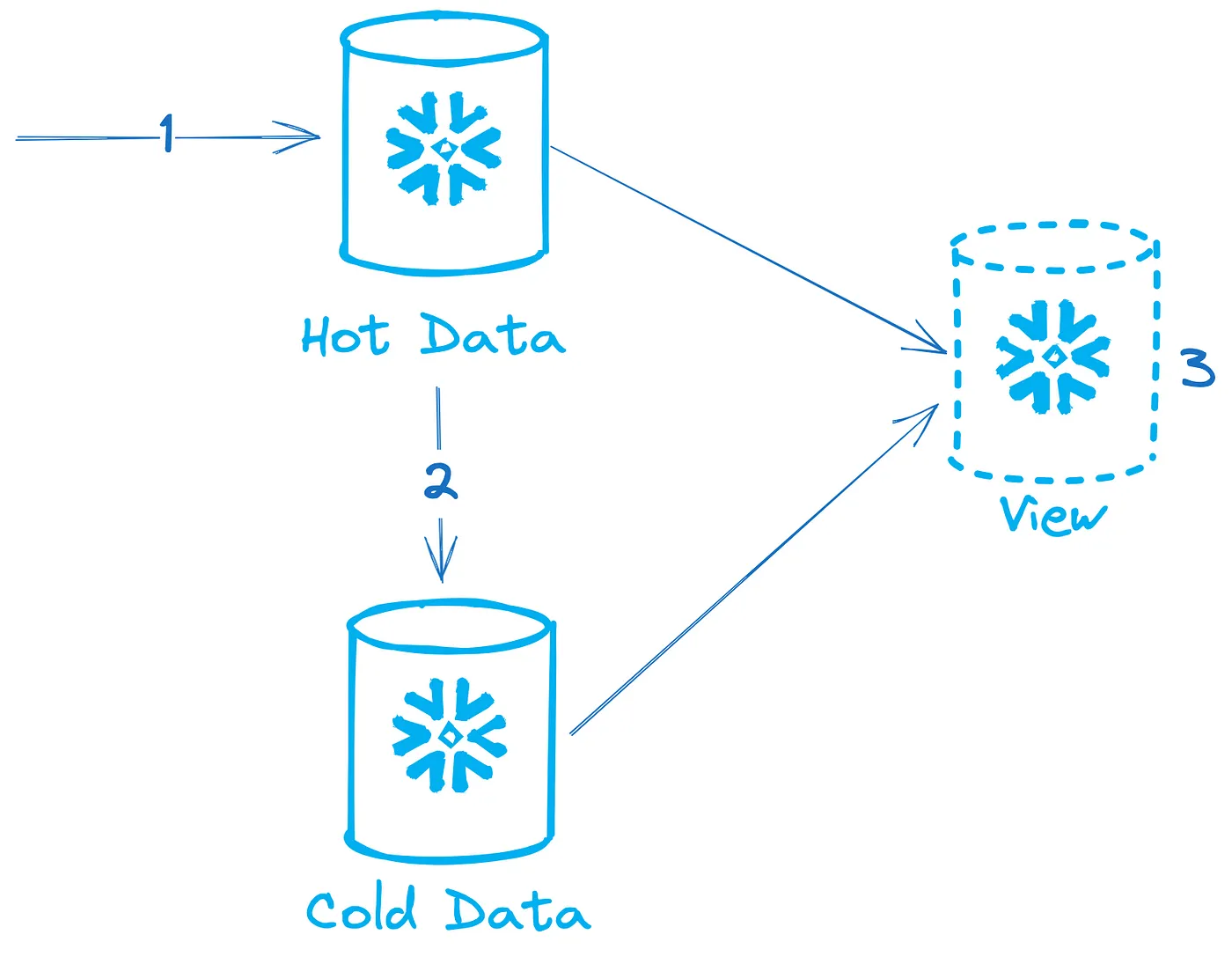
インジェスト
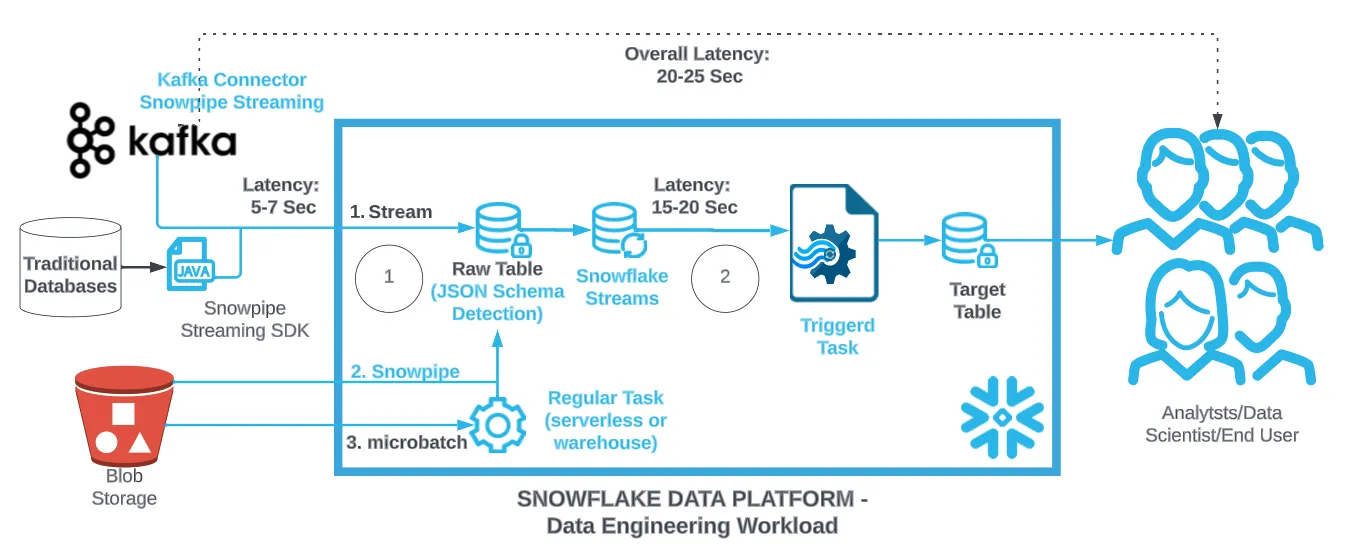

コストガバナンス

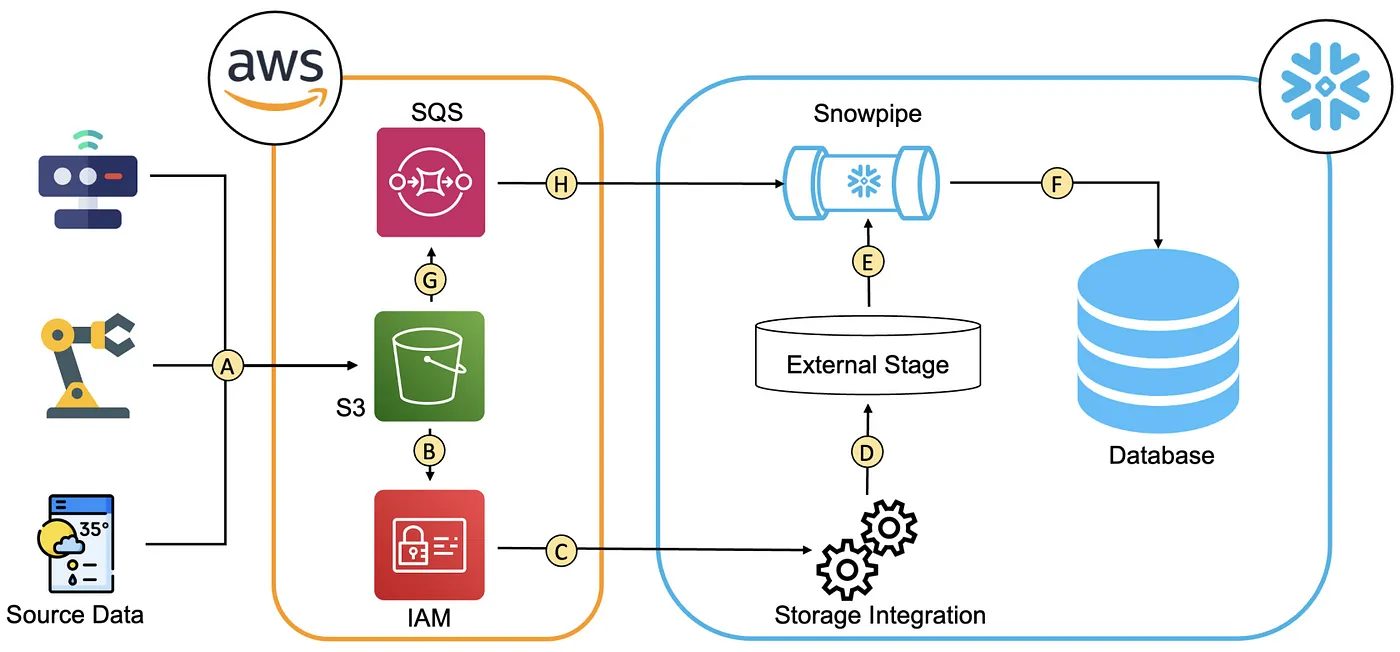
ストレージ
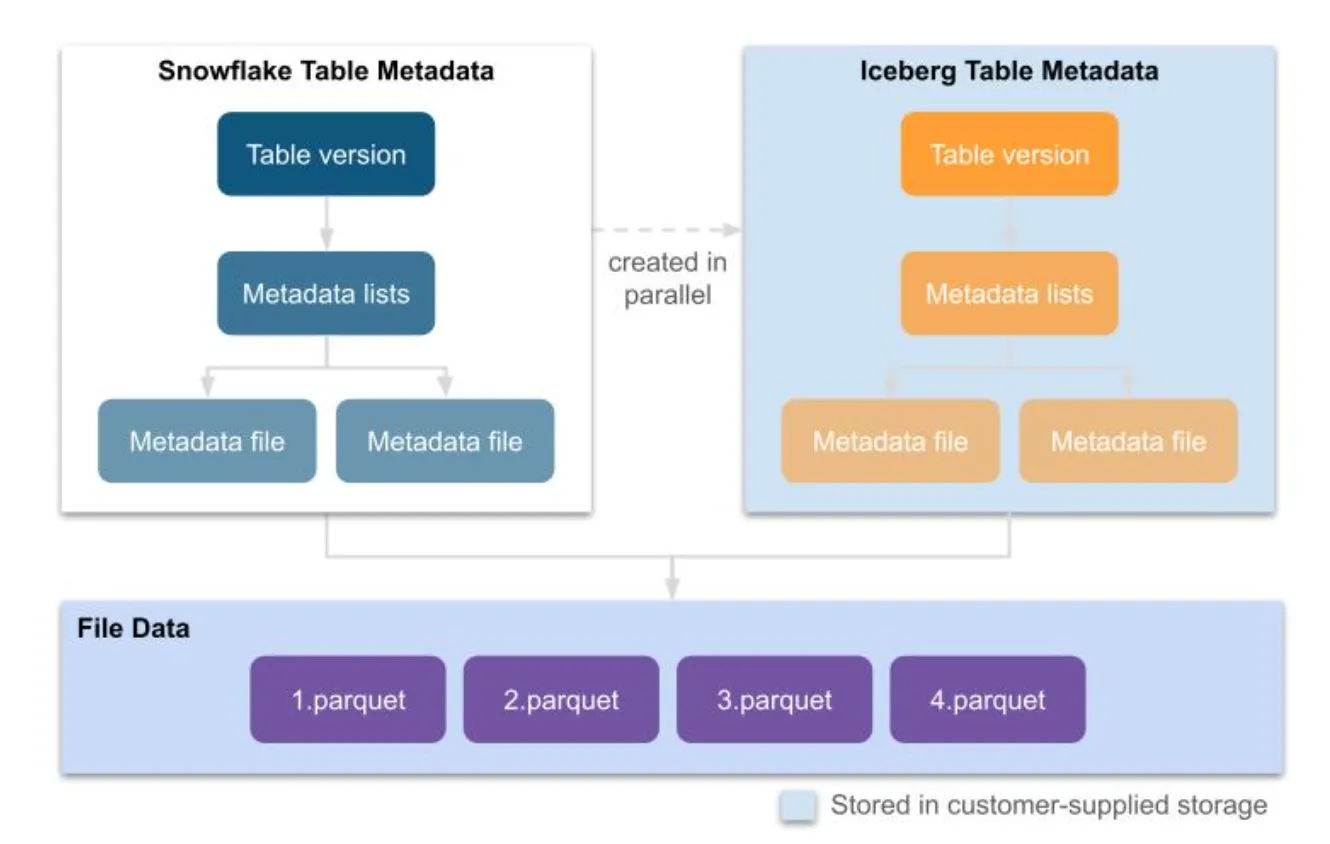
データレイク
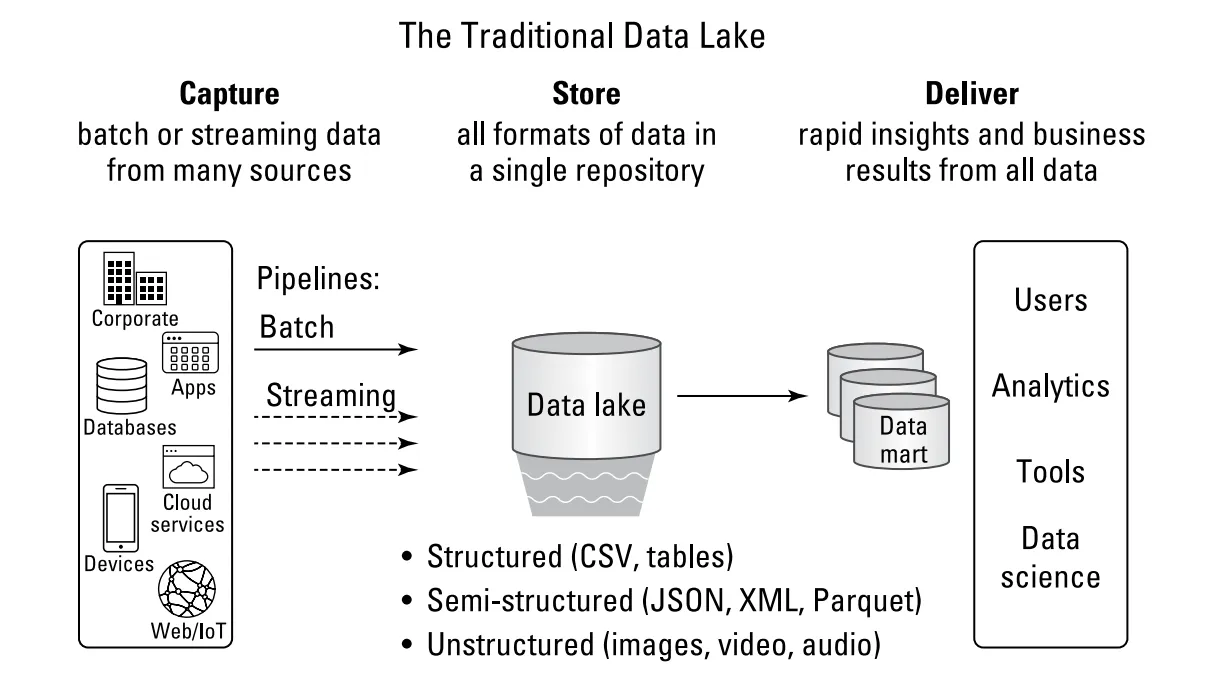
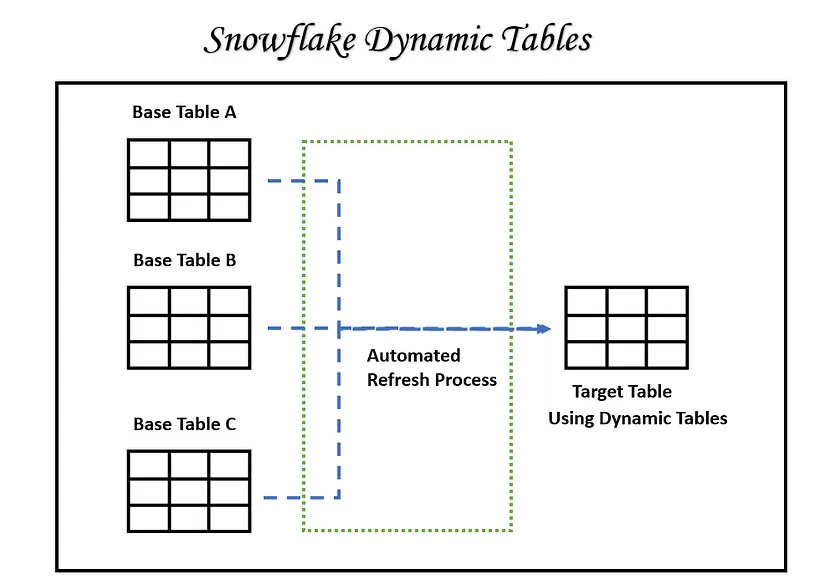
Dynamic Table
ストレージコスト最適化

セキュリティ・ガバナンス
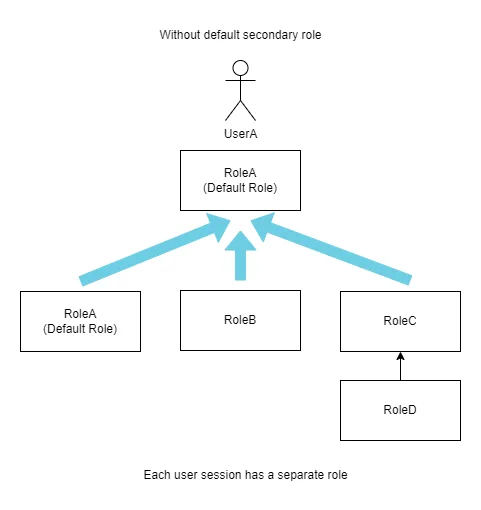
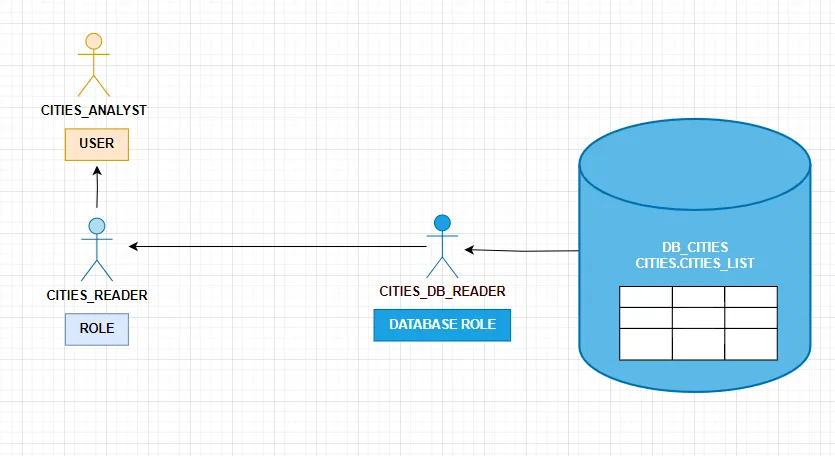
権限
開発
Git統合
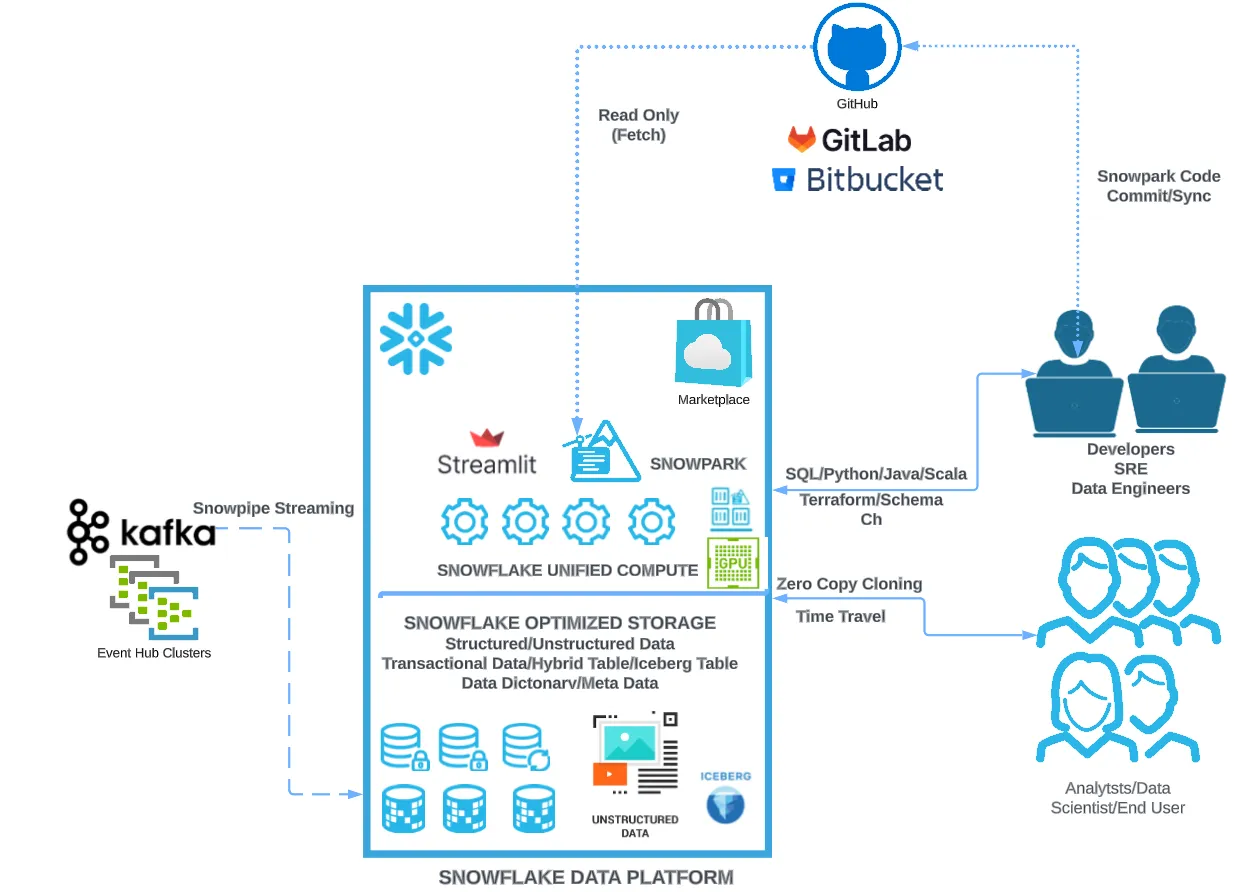
Git統合(PrPr)の書き方読んでみました。具体的。Workflowの改善がトピックなのだなとか。本体の機能が増えれば(小規模限定かもしれないが)本体だけで対応できる可能性が増えるということかなと。