




Snowpipeは外部ステージ上に置かれたファイルを自動的にSnowflakeテーブルにロードする仕組み。
クラウドプロバイダの機能が透過的に利用されるため、その仕組みを意識する必要がない。
AWS,Azure,GCPがサポートされている。
Snowpipeを設定する際に、登場するオブジェクトにどう権限設定したら良いのかいつも悩む。
オレオレ設定をしてガバくなってないか、調べ直してみて書いてみる。
セキュリティを構成する
SYSADMINでリソースを作って、SYSADMINにAssumeRoleして操作をする、というのは良くない。
別にロールを作ってそこに必要な権限を集めると良さそう。
既に外部ステージが存在し、そこに続々とファイルが配置されている。
また、既にSnowflakeにテーブルが存在し、外部ステージに到着するファイルを読み込みたい。
このシチュエーションで、外部ステージとSnowflakeテーブルを結ぶパイプを作成する。
パイプと関連する全リソースにアクセス可能なロールは以下のように作る。
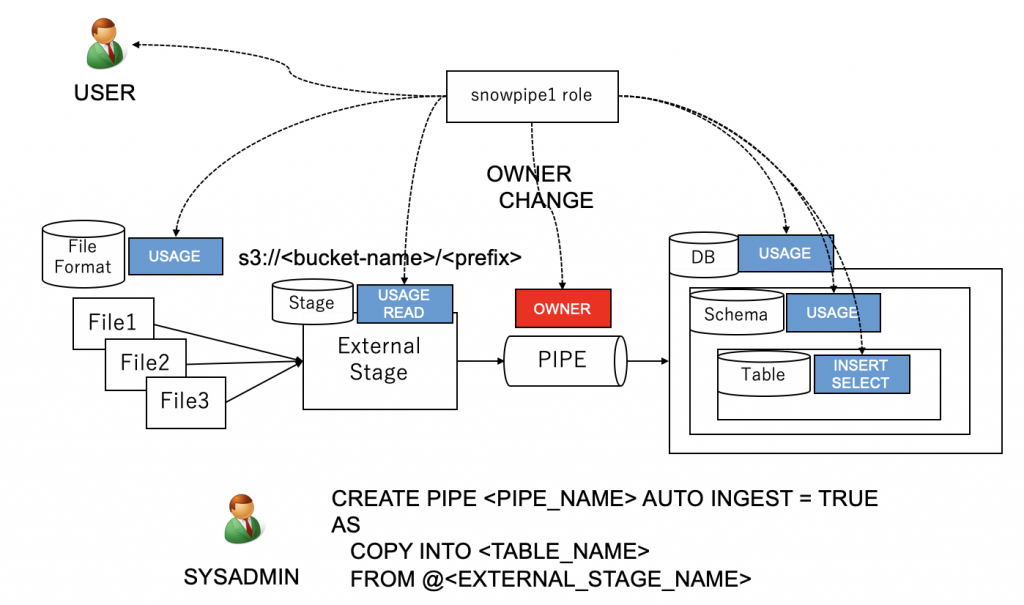
パイプから見れば、外部ステージ、テーブルは既存のオブジェクトであり、
使用する、つまり USAGE が必要。またデータ取得のため、外部ステージから READ が必要。
同様に、パイプから見れば、データベース、スキーマは既存のオブジェクトであり、
USAGEが必要。またデータ投入のため、テーブルに対して INSERT が必要。
パイプがテーブル内のデータを参照して処理をするため テーブルに大して SELECTが必要。
例えば SYSADMIN が PIPE を CREATE した場合、その所有者は SYSADMIN になるが、
これを繰り返すと、SYSADMIN が全ての所有者になってしまう。
今回、Snowpipeに関わるオブジェクトを操作・閲覧可能なロールを作る、という話なので、
新ロールを PIPE の所有者にする。
