




Hello CRISP-DM 1日目。
統計の基本は一応学びなおしたつもりなのと、
機は熟した感があり、Hotなところを突いてみる。
多変量解析と機械学習
多変量解析は、統計学の1分野で、人間が説明できるモデルを作ることが目的。
モデルができれば予測できるんじゃなかろうか、とも思うけども、
対比されちゃってるけど、統計学なんて凄まじい歴史がある訳で、
予測のための新しいツールとして機械学習があるという話。
モデルを説明することを放棄して、高性能な予測なり分類なりをしましょうと。
説明できないモデルを使って責任ある決定とか出来んのか、というのもあり。
完全に理解することを放棄するという位置付けでもない様子。
ルールベースと機械学習
予測器としての側面で、ルールベースとの比較がある。
密度関数が100%理解可能(予測値が出現する規則が100%理解可能)なのであれば、
いっそのこと全てif文で書けば良いわけで、わざわざ難しくする必要はなく..。
ルールベースの予測器を作ってみて結構上手く行った経験があって、
これはこれで何が起きても説明できるし、これで行けるならこれで良いかも。
Windows95の時代からある。
家賃予測してみる
家賃の予測モデル?を作るのを目的にCRISP-DMというプロセスを回す話。
ドメイン領域から目的変数と説明変数を取り出して、モデルを作って評価して、
正しくなさそうなら元に戻ってやり直す、という普通っぽいやり方にCRISP-DMという名前が付いてる。
データマイニングのプロセスで、特別に何か特別なツールを使わなければならない、ということはなし。
kaggleのTitanic..だと確かにリアル感がないのと、
結構、家賃だけでも知らないデータが埋もれてるものだな、と関心したり。
スクレイピングしてみる
suumoから地元の賃貸物件情報を取得して表示してみた。
スクレイピングするためのコードはこちらを参考にしてみた。
同時接続数が1なので4200件くらいの取得に8時間くらいかかってしまうけど、
待てば良い話なので、寝る前にスタートして起きたら確認。
ログだとかセンサーだとかWebだとか、いろいろなデータソースがあるけれども、
取ってくるためにはかなり泥臭い感じになるし、他に方法がないのかも。
なるべくコードを書かずに済ませたい、けども、致し方ないのかも。
Octparseで取ろうとしたらWindows専用でMacのは無いと言われ..。
散布図を作る
pandas(panel datas)というPython製のライブラリと、
seabornというPython製の描画ライブラリだけで簡単に散布図が出来る。
散布図出しただけで気分が良いな。
データが規則正しく並んでるのが気持ちが良いのか。
現実世界に存在する賃貸物件の情報が綺麗に2軸のグラフに収まってる。
もうこれだけで目的の半分くらいは達成したんじゃなかろうか..。
データの次数は5なので5×5の散布図ができる。
散布図作成時にある列に関して色分けできる機能があって、
試しに階数で色分けしてみた。微妙..。
suumoで期待した通りの書式になってなってないデータは0を入れてるので、
下限の0に張り付いてるデータが存在する。
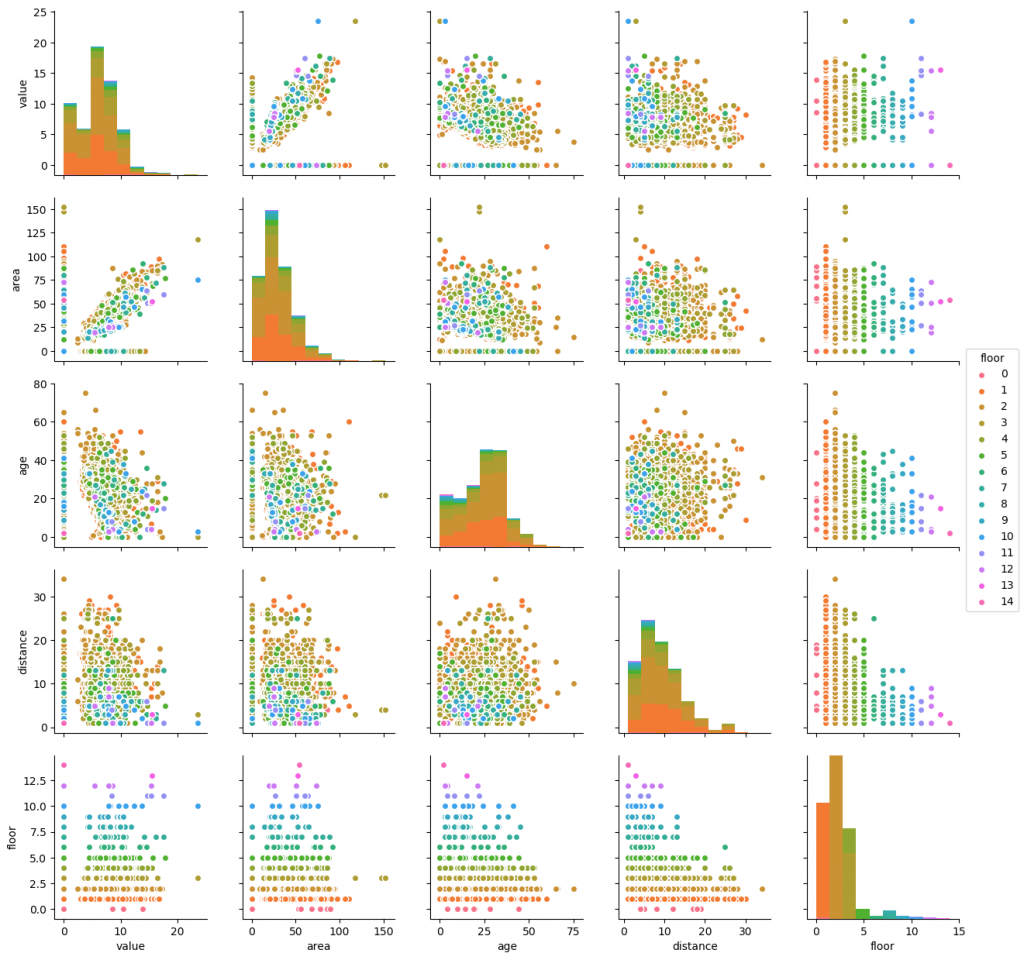
1Kとか2LDKとか、間取りの区別はしていないから同時に出る。
家賃と占有面積は関係があるということがわかる様子。
広い方が高いよ、は言える様子。
他の因子に引きずられず、築浅であろうが駅近であろうが、広さは正義らしい。
家賃と築年数は、全体的に右肩下がりだけども、
占有面積ほど関係があるとは言えない様子。
現実的には、築浅だとしても駅から遠ければお安い、という話があると思い..。
全体的に右肩下がりなので、そうであっても古ければ概ね安いという。
もっと意外なのは、家賃と最寄駅からの時間。
駅近であることが一番影響してそうに思ってたけどもそんなことはなかった。
確かに、駅近であっても古くて狭いのは安いからな。
占有面積と築年数ほど、家賃に影響を与えないらしい。
思い込みというのは怖いもの..。
多変量解析なら、どれの係数が高いかはここで当たりがつくけれども、
ランダムフォレストで家賃予測するとすると、どうなるか、次回に続く。