




やはりAWSの公式のドキュメンテーションは読みやすいので、
公式を上から順に舐めていくスタイルで理解していく。
今回は一番最初のアーキテクチャ概要。
アーキテクチャ
大きなデータを扱おうとする何かは分散アーキテクチャで解決しようとする。
と言っても、大抵は”代表するノード”と”ワーカーノード”のセットなのでデジャブ感がある。
ちなみにTableauServerが内部設計を細かく書いていて面白かった。
以下、Amazon Redshiftのアーキテクチャを表す図. (公式)
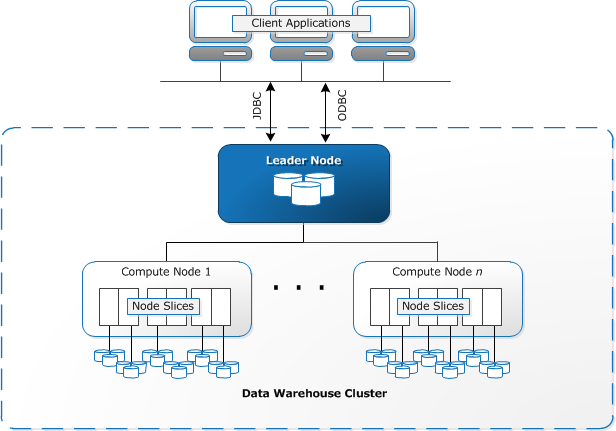
- Amazon Redshiftは複数のクラスタから構成される。
- クラスタはリーダーノードと複数のコンピューティングノードから構成される。
- クライアントアプリケーションからは唯一リーダーノードと呼ぶノードを参照できる。
- コンピューティングノードはクライアントアプリケーションから見えない場所に配置されリーダーノードが代表してコンピューティングノードを操作する。
リーダーノード
- クライアントアプリケーションは PostgreSQL用の JDBC/ODBCドライバを使用してリーダーノード通信できる。
- 実行計画に基づいてコードをコンパイルしコンパイル済みのコードをコンピューティングノードに配布してからデータの一部を各コンピューティングノードに割り当てる。
コンピューティングノード
- コンパイル済みのコードを実行し中間結果をリーダーノードに返送する。
- 中間結果はリーダーノードで最終的に集計される。
- コンピューティングノードのCPU、メモリ、ストレージはノードのタイプによって異なる。ノードの数、種類を増強することでスケールアップできる。
ノードスライス
- コンピューティングノードはスライスに分割されている。
- 各スライスにはノードのメモリとディスク容量の一部を割り当てられている。
- リーダーノードがスライスへのデータ分散を管理し、クエリ、データベース操作のワークロードをスライスに分配する。
- スライスは並列処理を行って操作を完了する。
内部ネットワーク
- リーダーノードとコンピューティングノードの間はプライベートで非常に高速なネットワーク。
- コンピューティングノードは独立したプライベートネットワークに配置される。
RDBとの互換性
- Amazon Redshift は PostgreSQLを大規模データ用に拡張したミドルウェアである。
- 標準的なRDBMSと同様にデータの挿入、削除、トランザクション処理を実行できる。行指向から列指向に拡張されており、行指向を前提としたクエリは苦手。
