




dbt Fundamentalsの「Models」のセクションについて、理解した内容を言葉にしてみた。
かなりの部分で感想を織り交ぜてみた。この記事は前回の記事(以下)の続き。

サーバーサイドエンジニアのデータベースエンジニア寄りの枠ぐらいの認識しかないと、 データエンジニアリングの尖った部分に永遠に近づけないという感触がある。 サーバーサイドエンジニアの入口から入った場合はちゃんとチェンジしないといけないな。 dbtが公式で「データエンジニアリングの用語と概念」を長い尺で説明していて学んでみた。 サーバーサイドエンジニア的にはETLは普通のジョブやバッチ処理だと思うが、 ELT化することで何を改善しようとしていて何が達成されたのか説明できるようになった。 dbt Fundamentals
実践的なコンテンツというよりは、概念の理解を優先した入門用のコンテンツであって、
これでモノを作れることはないと思うし、資格対策には不足していると思う。
動画の講師の方は自己紹介で教師のバックグラウンドがあると話されている。
個人的にはUdemyの類似品より構成と英語の発音がわかりやすいと感じる。
【目次】
- ∨クエリをバラして理解しやすいようにしたい
- ∨Modularity
- ∨CTEと論理レイヤとモデル
- ∨Materialization
- ∨モデルの例
- ∨モデリングの方法論とdbtの仮定
- ∨よもやま話(動画と関係なし)
- ∨まとめ
クエリをバラして理解しやすいようにしたい
関数型言語は、関数が再起的に評価されることで最終的な応答が確定する。
手続き型言語と異なり、再帰の評価の途中で一時停止して内容を観察することが難しい。
SQLは関数型言語ではないが、内包するSQLの評価を一時停止して観察することが難しい、
という点で近い。制御がない一筆書きである点が複雑さから逃れる理由になっていそう。
ビジネスロジックが乗った巨大なクエリは確かに一筆書きではあるが、理解しづらい。
クエリをバラしたら理解しやすいんじゃね? みたいな動機があるのだと思う。
ただバラして制御するとそれはもう手続きなので、バラすけど再利用するだけに留める。
バラして、途中経過を観察したり動きを制御したり、そういう仕組みをdbtが提供する。
Modularity
クエリをバラすことを、dbtでは「Modularity(モジュール性)」という用語で説明している。
動画では「車の製造」が例えとして挙げられている。パーツとパーツを繋げて車を製造すると。
Modularityは構造化されていて、上流(Upstream)から下流(Downstream)へと繋がる。
Upstreamで作ったパーツをDownstreamで再利用する、という仕組み。
1個1個のパーツは、CTE(Common Table Expression)を利用して表現される。
CTEは標準SQLに定義されていて、クエリの再利用性を高める表現手段。
要は、dbtはCTEを使ってクエリの再利用性を強制するF/Wなんだろうと思う。
CTEと論理レイヤとモデル
実際に動作する生クエリを書くのではなく、論理的な記述レイヤを設けている。
論理レイヤの記述フォーマットとして、jinjaテンプレートが採用されている。
jinjaテンプレートにマクロを記述することで論理レイヤの表現能力を獲得している様子。
Modularityの観点でCTEで各パーツを定義し、Up->Downのフローを論理的に定義する。
dbtが論理レイヤをコンパイルして物理SQLを吐くという仕様になっている。
このパーツのことをdbtでは「モデル」と呼んでいる様子。
1個のSELECT文が1個のモデルと対応する制約が与えられる。
これにより、Up側モデルをDown側モデルで再利用することと、クエリ結果の再利用を紐付けている。
Materialization
パーツは個別に具体的なSQLにコンパイルされる。これには「Materialize」という用語が付いている。
Upstream側を実体化する際、その実体化の手段を選択できる。
View
モデルをViewとして実体化する。実データを作らないので作るのが速いしストレージを食わない。
Viewに乗ったロジックが複雑だと所要時間が増えるので、その場合はTableの採用を考える。
CREATE VIEW AS … が使われる。
Table
モデルをTableとして実体化する。実データを作るので作るのに時間がかかるしストレージを食う。
ロジックが複雑であっても所要時間が増えない。BIから直接参照するとかならTableの採用を考える。
Up側にあるデータに追加や変更があっても反映されない。
CREATE (TRANSIENT) TABLE AS … が使われる。
Incremental
パイプラインを構築する際、「置き換え」なのか「増分」なのかは重要な観点となる。
初回生成時は通常のTableとして、2回目移行は増分だけを生成する。なので速い。
「増分」とする場合、どこが既存と増分の境界なのかを定義する必要がある。
その定義をモデルファイルに書く必要があり、若干複雑になる。
Ephemeral
中間テーブルをいちいちViewやTableに実体化し続けると、DWが再利用する可能性が低い何かで
埋め尽くされてしまうことがある。そういったテーブルはModularityの中で論理的に再利用したいが、
物理的に存在して欲しくない。それを実現できる。
Downstream側で1個か2個使うだけで、直接クエリを実行する必要がない場合に使うと良い。
モデルの例
動画では以下のクエリをdbt流に書く例が示されている。
以下は生クエリで、with句により3個のクエリを用意し4個目のクエリで結合している。
with customers as (
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
さて、次はdbtの論理レイヤの話。まずcustomersとordersをを別のファイルに記述する。
with customers as (
select
id as customer_id,
first_name,
last_name
from raw.jaffle_shop.customers
)
select * from customers
with orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from raw.jaffle_shop.orders
)
select * from orders
customersとordersを結合する。その際、customersとordersをref関数により参照する。
言い換えると、以下が評価される時点で、既にcustomersとordersは実体が存在する。
そのため、以下を評価する前に、customersとordersの中にあるデータを確認できる。
with customers as (
select * from {{ ref('stg_customers')}}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
dbt runコマンドにより、全てのモデルをコンパイルする。
また –selectをつけると、、特定のモデルだけコンパイルできる。
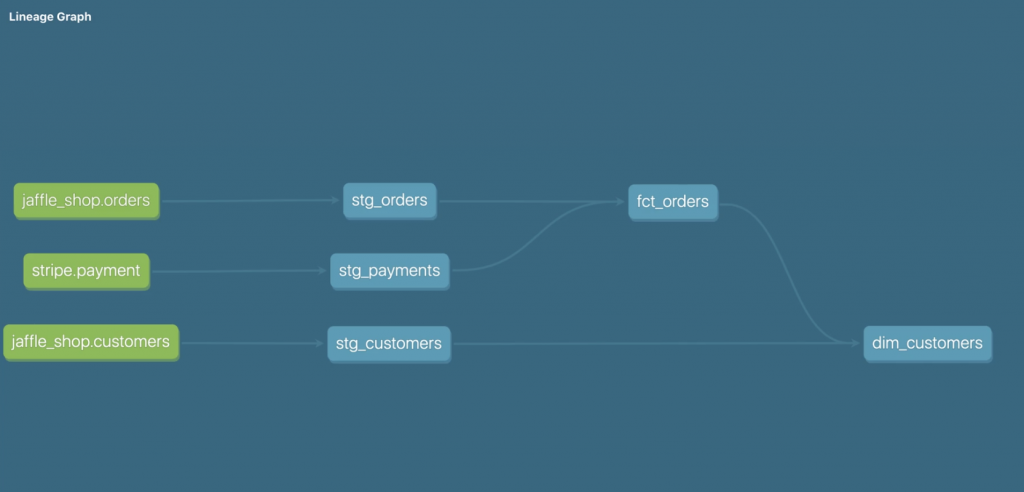
dbtには下図のようにモデル間の依存関係をグラフィカルに表示する機能がある。

モデリングの方法論とdbtの仮定
dbtは単なるクエリの変換ツールであって、現実世界のモデルする方法論を規定するものではない。
しかし、動画ではモデルのセクションでチラッとこの話に触れられている。
Fact TableとDimensional Tableに整理してDimension毎のFactを提供しましょう、
という流儀や、Kimball,Data Vaultのような流儀など、諸々存在する。
動画では、これらをTraditionalと分類し正規化がポイントであると言っている。
コンピューティングとストレージが安くなり、ELTが可能になったおかげで、
“正規化しない(Denormalized)”モデリング手法が実現可能になりましたよ、と言っている。
むむ.. 相当深そうだが入り口だけ。
いったん、ELTを前提としてモデルを組み上げてください、ぐらいの話として聞き取る。
ELTを前提として、モデルをこうレイヤリングし名前を付けますよと話されている。
Source
ELTであるが故に、外部のデータを無変換でDWに格納したところからスタートする。
そのレイヤを「Source」と名付ける。
Staging
Sourceレイヤのモデルのクレンジングと標準化を行うレイヤを「Staging」と名づける。
StagingモデルはSourceモデルと1:1対応させる。
Intermediate
Stagingモデルに対してビジネスロジックを適用して最終的なテーブルを生成する。
ビジネスロジックはダラダラと汚く大きくなることが常で、このレイヤで吸収する。
Fact
起きていること、または、既に起きたこと。履歴があるもの。
なんたらイベント、Webサイトにおけるクリック事象、投票など。
Dimension
時間の経過で発生するものではない履歴がない事象。
人、場所、コト、ユーザ、会社、製品、、顧客など。
以下は、動画で話されている実行例。
dbt-labs/jaffle_shop
https://github.com/dbt-labs/jaffle_shop
一番左の緑色のモデルがSource。外部から引っ張ってきたRawデータ。
Sourceと1対1対応する形で、「stg_*」という名前のStagingモデルが存在する。
Sourceに対してクレンジング、標準化を適用したデータ。
「fact_*」は、時間経過により発生する履歴データ、そして、「dim_*」は属性データ。
Down側からUp側へ、Source->Staging->Fact/Dimension という流れになっている。
よもやま話(動画と関係なし)
例えばLaravel/EloquentやRails/ActiveRecordにはQuery Builderが付いていて、
手続き型言語によってクエリのModularityを得るアプローチには既視感があると勝手に思っている。
もちろんクエリ結果をDWに統合できないから、DWに統合できるF/Wが必要なので、
そのアプローチはSnowflakeで言えばSnowparkによって扱われるのかなと思う。
手続き型言語ではソフトウエア開発の複雑さから逃れられないことになっている。
ちなみにORMにおける物理テーブルの抽象化において「モデル」という用語が充てられている。
少なくとも1990年代後半にはORMの文脈で物理テーブルを抽象化する概念は実用化されていた気がする。
2000年代には、オブジェクト指向分析設計の文脈で「現実世界のモデル化」がイキりたおされていた。
2010年代、Laravel/Eloquent, Rails/ActiveRecordでORMのモダニズムが言われてた。
手続きに持ち込まず、SQLの世界だけでモデル化が話されるのは新しい気がする。
ここは最初の「Analytics Engineers」の話に由来している気がする。
まとめ
dbt Fundamentalsの「Models」セクションを聴いて、内容を文書化してみた。
dbtはModularityと考え方に基づいてCTEによりクエリをバラすツールであることについて、
Modelの定義や実行例を追って確認してみた。
